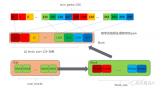
写在前面:笔者这段时间工作太忙,身心俱疲,博客停更了一段时间,现在重新捡起来。本文主要解读 OneFlow 框架的第二种 Softmax 源码实现细节,即 block 级别的 Softmax。
2024-01-08 09:26
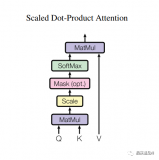
写在前面:近来笔者偶然间接触了一个深度学习框架 OneFlow,所以这段时间主要在阅读 OneFlow 框架的 cuda 源码。官方源码基于不同场景分三种方式实现 Softmax,本文主要介绍其中一种的实现过程,即 Warp 级别 Softmax,适用于矩阵宽度不
2024-01-08 09:24
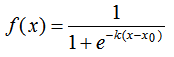
本文简单总结了机器学习最常见的两个函数,logistic函数和softmax函数。首先介绍两者的定义和应用,最后对两者的联系和区别进行了总结。
2018-12-30 09:04
这篇小文将告诉你:Softmax是如何把CNN的输出转变成概率,以及交叉熵是如何为优化过程提供度量,为了让读者能够深入理解,我们将会用python一一实现他们。
2018-07-29 11:21
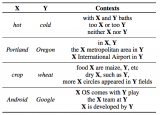
这种做法其实和词嵌入一脉相承。词嵌入同样面临计算所有上下文(softmax)过于复杂的问题。因此,word2vec、skip-gram等词嵌入技术使用了层次softmax(使用二叉树结构保存所有词
2018-11-12 09:38

首先来详细说明为什么Transformer的计算复杂度是 。将Transformer中标准的Attention称为Softmax Attention。令 为长度为 的序列, 其维度为 , 。 可看作Softmax Attention的输入。
2023-12-04 15:31
如果你只对以分类为目的的微调感兴趣,那么惯用的做法是丢掉栈式自编码网络的“解码”层,直接把最后一个隐藏层的 \textstyle a^{(n)} 作为特征输入到softmax分类器进行分类,这样,分类器(softmax)的分类错误的梯度值就可以直接反向传播给编码层
2019-06-11 16:09
对于图像分类问题,Dense层可能是不够的。但我们也可以另辟蹊径!有完整的卷积神经网络可供下载。我们可以切掉它们的最后一层softmax分类,并用下载的替换它。所有训练过的权重和偏差保持不变,你只需
2019-05-16 18:14
为了评估上述每个测试配置的性能,我制定的测试方案如下:使用相同的神经网络。也就是一个有 3 个卷积层和2个全连接层且在顶层带有Softmax的小型卷积神经网络
2019-01-24 11:25
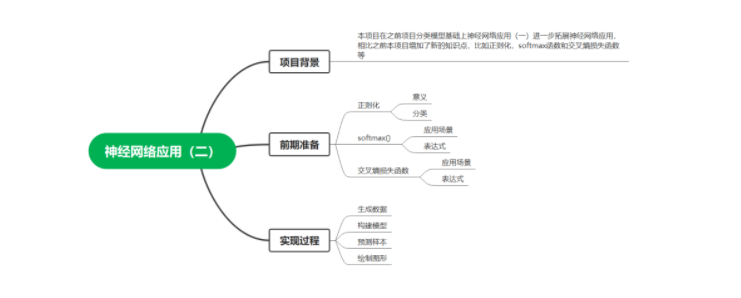
本项目在之前项目分类模型基础上神经网络应用(一)进一步拓展神经网络应用,相比之前本项目增加了新的知识点,比如正则化,softmax函数和交叉熵损失函数等。
2023-02-24 15:43