本文主要介绍一个被广泛使用的机器学习分类算法,K-nearest neighbors(KNN),中文叫K近邻算法。
2019-10-31 17:18
K近邻KNN(k-Nearest Neighbor)算法,也叫K最近邻算法,1968年由 Cover 和 Hart 提出,是机器学习算法中比较成熟的算法之一。K近邻算法使用的模型实际上对应于对特征空间的划分。KNN算法不仅可以用于分类,还可以用于回归。
2018-05-29 06:53
上面收的引入知识库+KNN的方法,缓解了模型参数需要强记忆训练样本的问题。此外,文中还通过KNN检索结果来指导模型的学习过程。
2022-10-09 17:33

k值得选取对kNN学习模型有着很大的影响。若k值过小,预测结果会对噪音样本点显得异常敏感。特别地,当k等于1时,kNN退化成最近邻算法,没有了显式的学习过程。若k值过大,会有较大的邻域训练样本进行预测,可以减小噪音样本点的减少;但是距离较远的训练样本点对预测结果会
2018-09-19 17:40
然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有点话就更新最近邻;如果不相交那就直接返回父节点的父节点,在另一个子树继续搜索最近邻
2019-02-04 10:29
很多网站登录都需要输入验证码,如果要实现自动登录就不可避免的要识别验证码。本文以一个真实网站的验证码为例,实现了基于一下KNN的验证码识别。
2018-12-24 17:27

作为『十大机器学习算法』之一的K-近邻(K-Nearest Neighbors)算法是思想简单、易于理解的一种分类和回归算法。
2018-01-02 14:56
朴素贝叶斯方法是一组基于贝叶斯定理的监督学习算法,在给定类变量值的情况下,朴素假设每对特征之间存在条件独立性。下面我将介绍几种朴素贝叶斯的方法。
2019-05-06 09:29
K-Means是十大经典数据挖掘算法之一。K-Means和KNN(K邻近)看上去都是K打头,但却是不同种类的算法。kNN是监督学习中的分类算法,而K-Means则是非监督学习中的聚类算法;二者相同之处是均利用近邻信息来标注类别。
2018-07-05 14:18
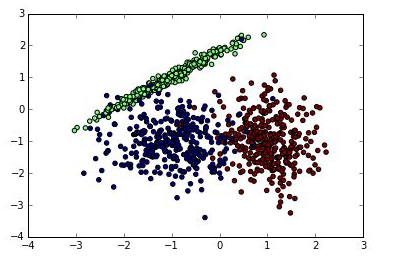
本文对scikit-learn中KNN相关的类库使用做了一个总结,主要关注于类库调参时的一个经验总结,且非常详细地介绍了类库的参数含义。
2019-01-13 11:49