如上图所示,sigmoid的作用确实是有目共睹的,它能把任何输入的阈值都限定在0到1之间,非常适合概率预测和分类预测。但这几年sigmoid与tanh却一直火不起来,凡是提及激活函数,大家第一个想到的就是ReLU,为什么?
2018-06-30 08:55
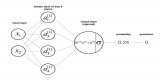
在定义好网络结构并初始化参数完成之后,就要开始执行神经网络的训练过程了。而训练的第一步则是执行前向传播计算。假设隐层的激活函数为 tanh 函数, 输出层的激活函数为 sigmoid 函数。则前向传播计算表示为:
2018-07-26 17:22
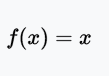
ReLU(Rectified Linear Unit,修正线性单元)训练速度比tanh快6倍。当输入值小于零时,输出值为零。当输入值大于等于零时,输出值等于输入值。当输入值为正数时,导数为1,因此不会出现sigmoid函数反向传播时的挤压效应。
2018-05-16 11:18
、tanh、ReLU(Rectified Linear Unit 线性修正单元)和以及这些函数的变体。 二、Adadelta Adadelta 是基于梯度下降的学习算法,可以随时间调整每个参数的学习率
2017-12-08 10:36