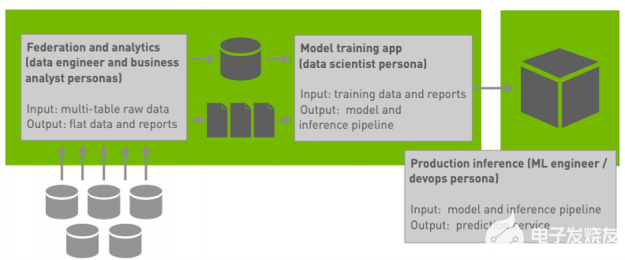
在第三期文章中,我们详细介绍了如何充分利用 Apache Spark 和 Apache RAPIDS 加速器 Spark 。 大多数团队都会通过干净地使用 Spark 的数据帧抽象来实现最大
2022-04-26 17:39
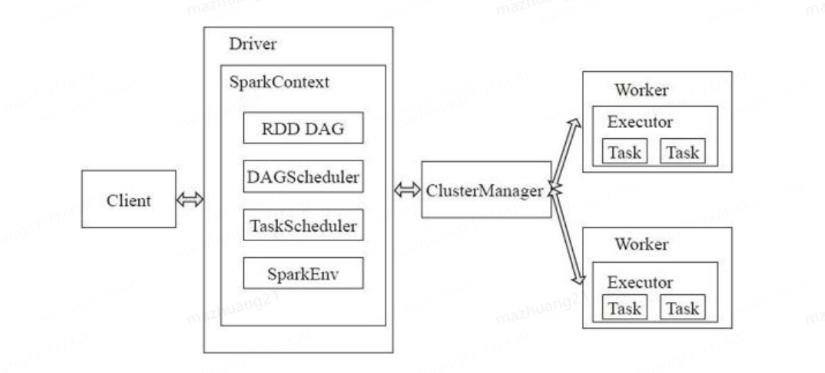
前言: 由于最近对spark的运行流程非常感兴趣,所以阅读了《Spark大数据处理:技术、应用与性能优化》一书。通过这本书的学习,了解了spark的核心技术、实际应用场景以及性能优化的方法。本文旨在
2024-07-02 10:31
经过七轮投票, Apache Spark 3.2 终于正式发布了。Apache Spark 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照
2021-11-17 14:09
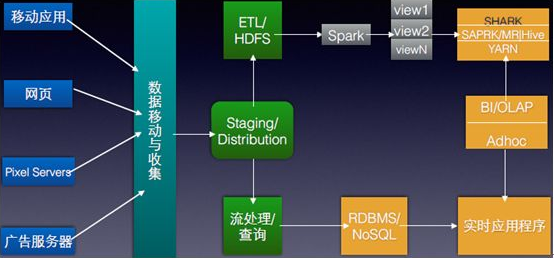
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
2018-02-12 14:41
spark为什么比mapreduce快? 首先澄清几个误区: 1:两者都是基于内存计算的,任何计算框架都肯定是基于内存的,所以网上说的spark是基于内存计算所以快,显然是错误的 2;DAG计算模型
2024-09-06 09:45
另一个答案是安装Spark CLI工具和Spark Dev IDE,或者甚至设置了单独的Spark Source环境。这些将需要等待将来的Instructable。
2019-11-05 08:41

Synchronized multi-spark module (SMSM) for Electronic Ignition Devices (EID)
2009-12-29 09:09
涉及磁盘的读写和网络 I/O,因此 Shuffle 性能的高低直接影响整个程序的性能。Spark 也有 Map 阶段和 Reduce 阶段,因此也会出现 Shuffle 。 Spark Shuffle
2021-10-11 11:15
一、Spark SQL的概念理解 Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成
2021-09-02 15:44

Ada 和 SPARK 方法的独特之处在于它集成了软件规范、实现和验证,提供了一种以现代系统所需的完整性级别生产软件的经济高效的方法。医疗、汽车和工业物联网 (IIoT) 等行业一直在寻找传统 C 语言开发的替代方案,Ada 和 SPARK 提供了经过验证的解
2022-06-29 14:33