
大模型混合多种能力项数据进行微调时,会呈现高资源冲突,低资源增益的现象。我们提出的DMT策略通过在第一阶段微调特定能力数据,在第二阶段微调通用数据+少量的特定能力数据。
2023-10-26 14:14

而这一切的背后,是一项名为Sorted Fine-Tuning(SoFT)的新训练技术。SoFT让我们可以在一个训练周期内产出多个子模型,无需任何额外的预训练步骤。此外,这项技术还揭示了模型的中间层也能够产生高质量的输出,这一点在之前的研究中常常被忽视。
2023-09-26 16:26

文章目录 系列文章0x0. 前言0x1. Supervised finetuning (SFT) 教程翻译 如何训练模型 如何对SFT checkpoint进行评测? 模型和数据 来自
2023-07-06 15:31

DISC-LawLLM是基于我们构建的高质量数据集DISC-Law-SFT在通用领域中文大模型Baichuan-13B上进行全参指令微调得到的法律大模型。值得注意的是,我们的训练数据和训练方法可以被适配到任何基座大模型之上。
2023-09-28 17:34
Reward Model的初始化:6B的GPT-3模型在多个公开数据((ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande)上fintune。不过Paper中提到其实从预训练模型或者SFT模型开始训练结果也差不多。
2024-01-09 12:12
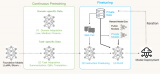
我们主要用一个具体的例子展示如何在两个框架下做RLHF,并且记录下训练过程中我们踩到的主要的坑。这个例子包括完整的SFT,奖励建模和 RLHF, 其中RLHF包括通过 RAFT 算法(Reward rAnked FineTuning)或者TRL-PPO 对齐模型两个部分。
2023-06-20 14:36