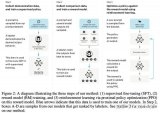
Reward Model的初始化:6B的GPT-3模型在多个公开数据((ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande)上fintune。不过Paper中提到其实从预训练模型或者SFT模型开始训练结果也差不多。
2024-01-09 12:12

尽管鲁迅先生曾言:真的强化敢于直面惨淡的结果,敢于正视崩坏的曲线。但日复一复地开盲盒难免会让人心脏承受不了,好在前人们留下了宝贵的驯化经验,今天让我们一起看看“如何稳定且有效地训练PPO”。
2023-11-16 11:41
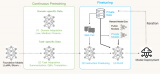
我们主要用一个具体的例子展示如何在两个框架下做RLHF,并且记录下训练过程中我们踩到的主要的坑。这个例子包括完整的SFT,奖励建模和 RLHF, 其中RLHF包括通过 RAFT 算法(Reward rAnked FineTuning)或者TRL-PPO 对齐模型两个部分。
2023-06-20 14:36
基于ML-Agents可以将自动驾驶车辆摄像头获取道路的图片信息,发送给Python的训练模型,利用图像识别提取图片中的参数信息。例如:前方障碍物的分类,距离以及运动方向的判断,发送给PPO训练模型,并将模型输出的命令发送回车辆,控制车辆在虚拟环境中行驶。
2018-07-09 16:33
为了评价新型算法的表现,研究人员首先在仿真环境中利用标准的基准任务来对SAC进行了评测,并与深度确定性策略梯度算法(DDPG),孪生延迟深度确定性策略梯度算法(TD3),邻近策略优化(PPO)等算法进行了比较。几种算法在三种基本的模拟移动任务上进行了性能比较,分别是豹,蚂蚁和人形。
2018-12-20 10:31

~ = +125°C时,具有165mΩ (最大)低导通电阻。驱动电阻负载时,高边开关的输入至输出传输延迟为2μs (最大)。推挽式操作的PWM/PPO控制中,开关频率达100kHz,可驱动长电缆。可将多个高边开关并联,实现较高驱动电流。器件具有较宽的10V至36V电源输入范围。
2025-05-21 14:12
