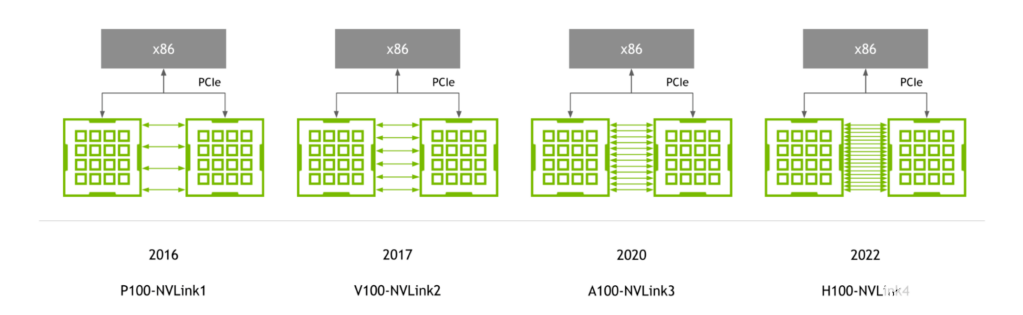
2014年,NVLink 1.0发布,并应用在P100芯片上,如下图所示。两颗GPU之间有4条NVlink, 每个link中包含8个lane, 每条lane的速率是20Gb/s, 因此整个系统的双向带宽为160GB/s,是PCIe3 x16带宽的5倍。
2023-10-11 15:32
本文详细阐述了 NVIDIA NVLink Fusion 如何借助高效可扩展的 NVIDIA NVLink scale-up 架构技术,满足日益复杂的 AI 模型不断增长的需求。
2025-09-23 14:45
计算机网络通信中两个重要的衡量指标是带宽和延迟,AI 网络也是如此。在向百亿级及以上规模的发展过程中,影响AI计算集群性能的关键并不只在于单个芯片的处理速度,每个芯片之间的通信速度也尤为重要。
2023-10-17 11:25
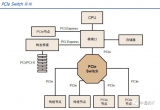
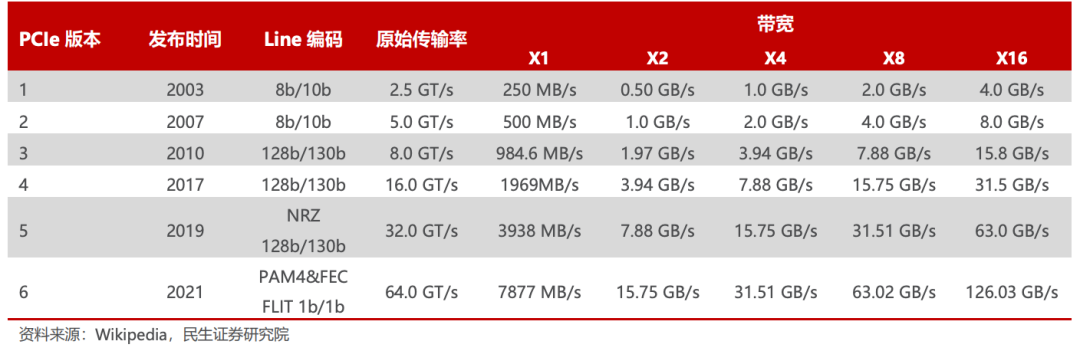
总线是数据通信必备管道,PCIe 是最泛使用的总线协议。总线是服务器主板上不同硬件互相进行数据通信的管道,对数据传输速度起到决定性作用,目前最普及的总线协议为英特尔 2001 年提出的 PCIe(PCI-Express)协议
2023-12-13 16:26
NVLink技术取代了SLI技术,可以配合Quadro NVLink 2-Slot或者3-Slot使用。NVLink技术不但具备多卡同步输出的功能,在应用支持的情况下,还能实现显存叠加的功能,使两块卡叠加成一个更大的
2019-04-17 16:50

最近Intel Gaudi-3的发布,基于RoCE的Scale-UP互联,再加上Jim Keller也在谈用以太网替代NVLink。
2024-04-22 17:22
这个 第三代 NVIDIA NVSwitch 设计用于满足这种通信需求。最新的 NVSwitch 和 H100 张量核心 GPU 使用第四代 NVLink ,这是 NVIDIA 最新的高速点对点互连。
2022-10-11 09:35
流行的GPU/TPU集群网络组网,包括:NVLink、InfiniBand、ROCE以太网Fabric、DDC网络方案等,深入了解它们之间的连接方式以及如何在LLM训练中发挥作用。为了获得良好的训练性能,GPU网络需要满足以下条件。
2023-12-25 10:11
用于大语言模型(LLM)推理的 H100 NVL。H100 NVLGPU 适用于大规模部署 ChatGPT 等大型 LLM。H100 NVL 通过 NVLINK 将两张 H100 PCIE 桥接在一起,其中的每张卡拥有 94GB HBM3 内存,同时内置 Transformer 引擎。
2023-03-28 09:28

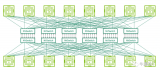
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);
2023-12-27 16:49