
你现在可以尝试在 Grafana 中创建子文件夹来组织你的仪表盘和警报。你可以在你的开发环境中启用这个新功能,以创建、阅读、更新和删除子文件夹,使其更容易按业务单位、部门和团队对资源进行分类。
2023-06-26 17:06
对于弹性伸缩和高可用的系统来说,一般有大量的指标数据需要收集和存储,如何为这样的系统打造一个监控方案呢?本文介绍了如何使用 Thanos+Prometheus+Grafana 构建监控系统。
2022-05-05 21:14

你可能已经看过了Lucas Palmieri的博客文章Are we observable yet? An introduction to Rust telemetry。如果你还没有看过,我们建议阅读一下,因为它提供了一个全面的介绍,介绍了如何处理 Rust 代码中的日志。
2023-06-27 11:36
这里 management.endpoints.web.exposure.include=* 配置为开启 Actuator 服务,因为Spring Boot Actuator 会自动配置一个 URL 为 /actuator/Prometheus 的 HTTP 服务来供 Prometheus 抓取数据,不过默认该服务是关闭的,该配置将打开所有的 Actuator 服务。
2022-12-26 16:02
在 MindIE 服务化运行过程中,为了及时掌握服务的运行状态、性能表现以及发现潜在问题,提供了服务监控指标查询接口(普罗 (Prometheus) 格式)。该接口能够帮助开发者和运维人员获取丰富的服务监控指标数据,为优化服务配置、保障服务质量提供有力支持。
2025-04-21 11:48
Loki 是一个由Grafana Labs 开发的开源日志聚合系统,旨在为云原生架构提供高效的日志处理解决方案。
2023-02-23 10:26
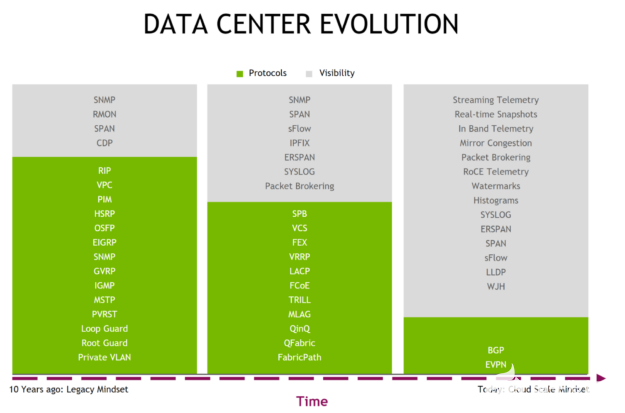
NetQ的能力远远超出了这篇文章中所展示和讨论的内容,并且其功能还包含设备库存、软件生命周期管理、基于阈值的警报以及与第三方平台(如Slack、PagerDuty和Grafana)的集成。NetQ将继续扩展并增加更多的功能和第三方集成,在未来为用户创造更多价值。
2022-04-17 10:25
│ ├── grafana-fuzz.txt│ ├── interesting-metacharacter.txt│ ├── null-fuzz.txt│ └── url-hex-fuzz.txt
2023-06-26 09:50
在云原生的生态下,kubernetes 已经被越来越多地应用到公司实际生产环境中。在这样的生态环境下系统监控、业务监控和数据库监控指标都需要在第一时间获取到,目前用的最多的也是prometheus、exporter、grafana、alertmanager这几个软件组建起来构建自己的监控系统。
2022-10-11 09:49