带有这样的偏见的词嵌入模型,会给下游的NLP应用带来严重问题。例如,基于词嵌入技术的简历自动筛选系统或工作自动推荐系统,会歧视某种性别的候选人(候选人的姓名反映了性别)。除了造成这种明显的歧视现象,有偏见的嵌入还可能暗中影响我们日常使用的NLP应用。
2018-09-23 09:25
对于IDF而言,长文档包含的单词更多,因此更容易出现各种单词。因此,IDF相等的情况下,经常出现在短文档中的单词,信息量比经常出现在长文档中的单词要高。例如,假设100篇文档中,有2篇提到了“手机”,有2篇提到了“平板”,那么这两个单词的IDF值均为log(1 + 100/2) = 3.932。
2018-06-25 14:50

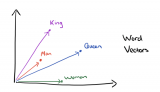
面我们介绍了 Word Embedding,怎么把一个词表示成一个稠密的向量。Embedding几乎是在 NLP 任务使用深度学习的标准步骤。我们可以通过 Word2Vec、GloVe 等从未标注数据无监督的学习到词的 Embedding,然后把它用到不同的特定任务中。
2019-01-20 09:24

作者发现,在决定BERT-embedding和Glove-embedding的效果性能方面,训练数据量起着关键作用。通过使用更多的训练数据,非上下文嵌入很快得到了改善,并且在使用所有可用数据时,通常能够在BERT模型用
2020-08-28 10:44

最近我们尝试用无监督学习增强系统,进一步研究语言能力。无监督技术训练能通过含有巨大信息量的数据库训练单词的表示,与监督学习结合后,模型的性能会进一步提高。最近,这些NLP领域的无监督技术(例如GLoVe和word2vec)利用了简单模型(词向量)和训练信号。
2018-06-30 09:20