发文章
发资料
发帖
提问
发视频
0
搜索热词
GD32E230 系列是 GD 最新推出的 Cortex_M23 系列产品,该系列资源上与既有的 GD32F1x0 以及 GD32F3x0 兼容度非常高。由于
2024-09-04 09:38 聚沃科技 企业号
GD32E503 系列是 GD 推出的 Cortex_M33 系列产品,该系列资源上与 GD32F303 兼容度非常高,本应用笔记旨在帮助您快速将应用程序从 GD32F
2024-08-31 09:36 聚沃科技 企业号
参考例程是基于GD32F450的,在移植过程中遇到一些容易忽略的地方,导致程序卡在gd32fxx_enet.c中enet_phy_config的位置。将GD32F450上的代码全部移植到
2024-01-16 08:00 撞上电子 企业号
GD32E230 系列是 GD 的 Cortex_M23 系列产品,GD32F330 系列是 GD 的 Cortex_M4 系列产品, 这两个系列的兼容度非常高。客户会
2024-09-03 10:05 聚沃科技 企业号
本应用笔记旨在帮助您快速将基于 GD32F10x 2.0 版本及以上固件库开发的应用程序从GD32F10x 系列微控制器移植到 GD32E103 系列微控制器。GD32
2024-09-05 09:40 聚沃科技 企业号
自Google提出Vision Transformer(ViT)以来,ViT渐渐成为许多视觉任务的默认backbone。凭借着ViT结构,许多视觉任务的SoTA都得到了进一步提升,包括图像分类、分割、检测、识别等。
2022-10-31 17:03
本文探讨了普通视觉Transformer(ViT)用于语义分割的能力,并提出了SegViT。以前基于ViT的分割网络通常从ViT的输出中学习像素级表示。不同的是,本文利用基本的组件注意力机制生成语义分割的Mask。
2022-10-31 09:57
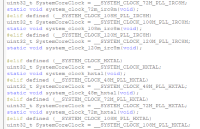
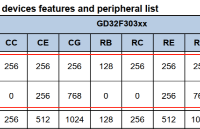
GD32F30x 系列 MCU 是基于 Arm® Cortex®-M4 处理器的 32 位通用微控制器,与 STM32F10x 系列 MCU 保持高度兼容。本文主要从以下三个方面进行介绍:硬件资源
2024-09-07 09:57 聚沃科技 企业号
GD32F4xx 系列 MCU 是基于 Arm® Cortex®-M4 处理器的 32 位通用微控制器,与 STM32F4xx系列 MCU 保持高度兼容。本文主要从以下三个方面进行介绍:硬件资源对比
2024-09-06 09:40 聚沃科技 企业号
在MCU开发中,有一项非常重要的参数——MCU启动时间,即MCU上电后到程序开始运行这段时间。我们来看下GD32F303的datasheet中对启动时间的描述:
2024-02-22 11:11 聚沃科技 企业号