
在具体实现过程中,基于Mask R-CNN提出了一种新颖的迁移学习方法。Mask R-CNN可以将实例分割问题分解为边框目标检测和掩膜预测两个子任务。在训练中分类信息会被编码到边框头单元中,就可以将这一视觉类别信息迁移到部分监督的掩膜头中去。
2018-06-20 16:45
长久以来,我们的思维倾向于陷入舒适区。当 A 做了物体检测,我们尝试改网络,改 loss,别的领域 trick 拿来就是一篇。而我们常常忽略了更为重要的问题,到底这个问题的该如何定义,这点极为重要。
2019-03-10 09:46

如上图所示,以前的医学图像分割 UDA 方法大多采用 2D UDA,当将预测堆叠在一起时,会导致切片方向上的预测不一致。SDC-UDA 在翻译和分割过程中考虑了体积信息,从而改善了分割结果在切片方向上的连续性,可以看到在图的最右侧,下面方法的 Dice 值在切片方向上是稳定的。
2023-08-17 16:35

与以往基于学习的视觉定位算法的区别在于:以前的方法往往需要数小时或数天的训练,而且每个新场景都需要再次进行训练,使得该方法在大多数应用程序中不太现实,所以在本文中作者团队提出的方法改善了这一确定,使得可以在不到5分钟的时间内实现同样的精度。
2023-06-05 17:26
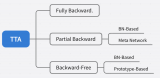
TTA 在语义分割中的应用,效率和性能都至关重要。现有方法要么效率低(例如,需要反向传播的优化),要么忽略语义适应(例如,分布对齐)。此外,还会受到不稳定优化和异常分布引起的误差积累的困扰。
2023-06-30 15:13

在传统的三维物体检测任务中,前景物体通常由三维边界框表示。然而,这种方法存在一些弊端,一方面,现实世界的物体几何形状非常复杂,无法用简单的三维框表示;另一方面,这种方法容易忽略背景元素的感知。对于实现全面的 L4/L5 自动驾驶,传统的三维感知方法是远远不够的。
2023-06-21 14:04

再次回到图 1 中的红色插框,本文由此得出结论,两个点集只有从大量点云学习到统计规则之后才相连,并观察这一类型的诸多物体,伴随着从椅子延伸到地面的相连、垂直的元素。这启发本文采取一种学习的方法来捕捉点云的拓扑学结构。
2019-03-29 16:31

EcoTTA 包括解决这些问题的两个组成部分。第一个组件是轻量级元网络,它可以使冻结的原始网络适应目标域。这种架构通过减少反向传播所需的中间激活量来最大限度地减少内存消耗。
2023-07-04 11:00

过去十年,对基于数据驱动的可供性感知的计算模型重新产生了兴趣。早期的研究采用了中介方法,通过推断或使用中间语义或3D信息来辅助可供性感知。一些难以预测的可供性例子包括涉及物体之间复杂交互或需要更高层次推理和对场景上下文的理解。
2023-06-09 16:52
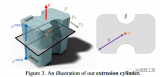
(i)实例分割 :定义将每个点分配给某个片段 k{1 ...K} 的可能性,其中每个片段都是挤压柱面(ii) 基础桶分割:实例化为 ,表示桶点,表示底座(iii) 表面法线 N ∈ RNX3对此,建立一个神经网络
2023-10-12 16:49