虽然GPT-3没有开源,却已经有人在复刻GPT系列的模型了。 例如,慕尼黑工业大学的Connor Leahy,此前用200个小时、6000RMB,复现了GPT-2。 又例如,基于150亿参数
2021-02-13 09:24

据 NVIDIA 估算,如果要训练GPT-3 ,即使单个机器的显存/内存能装得下,用 8 张 V100 的显卡,训练时长预计要 36 年。
2021-05-19 11:06
经典 Transformer 使用不可学习的余弦编码,加在模型底层的词向量输入上。GPT、BERT将其改为可学习的绝对位置编码,并沿用到了RoBERTa、BART、GPT-2、GPT-3等经典模型。
2023-11-17 17:31
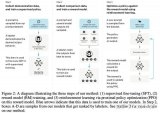
Reward Model的初始化:6B的GPT-3模型在多个公开数据((ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande)上fintune。不过Paper中提到其实从预训练模型或者SFT模型开始训练结果也差不多。
2024-01-09 12:12

本文介绍了支持 ChatGPT 的机器学习模型的概况,文章将从大型语言模型的介绍开始,深入探讨用来训练 GPT-3 的革命性自我注意机制,然后深入研究由人类反馈的强化学习机制这项让 ChatGPT 与众不同的新技术。
2023-05-26 11:44

从 GPT-3,Gopher 到 LLaMA,大模型有更好的性能已成为业界的共识。但相比之下,单个 GPU 的显存大小却增长缓慢,这让显存成为了大模型训练的主要瓶颈,如何在有限的 GPU 内存下训练大模型成为了一个重要的难题。
2023-09-11 16:08
Prompt tuning 的关键思想是将任务特定的 embedding 注入隐藏层,然后使用基于梯度的优化来调整这些 embeddings。然而,这些方法需要修改模型的原始推理过程并且获得模型梯度,这在像 GPT-3 和 ChatGPT 这样的黑盒 LLM 服务中是不切实际的。
2023-04-03 14:16
自然语言生成(又称为文本生成)旨在基于输入数据用人类语言生成合理且可读的文本。随着预训练语言模型的发展,GPT-3,BART等模型逐渐成为了生成任务的主流模型。近年来,为了利用预训练阶段编码的丰富知识,提示学习成为了一个简单而强大的方法。
2022-10-14 15:38
这是一组由 Meta 开源的大型语言模型,共有 7B、13B、33B、65B 四种版本。其中,LLaMA-13B 在大多数数据集上超过了 GPT-3(175B),LLaMA-65B 达到了和 Chinchilla-70B、PaLM-540B 相当的水平。
2023-06-11 11:24

BERT和 GPT-3 等语言模型针对语言任务进行了预训练。微调使它们适应特定领域,如营销、医疗保健、金融。在本指南中,您将了解 LLM 架构、微调过程以及如何为 NLP 任务微调自己的预训练模型。
2024-01-19 10:25