如果想减少GPU闲置时间,我们可以在管道末尾添加tf.data.Dataset.prefetch(buffer_size),其中buffer_size这个参数表示预抓取的batch数,我们一般设buffer_size=1,但在某些情况下,尤其是处理每个batch耗时不同时,我们也可以适当扩大一点。
2018-12-03 09:08
首先对于查询是否存在的操作我们选择用dict来做(hash速度快), 对整个字符串进行遍历 用dict字典中存储已经访问过的数据. 对于未存在于dict中的元素直接添加key:value为s[i
2023-03-01 13:37
对于 dict 和 list 等数据结构的对象,直接赋值使用的是引用的方式。而有些情况下需要复制整个对象,这时可以使用 copy 包里的 copy 和 deepcopy,这两个函数的不同之处在于后者是递归复制的。效率也不一样:(以下程序在 ipython 中运行)
2018-05-01 17:38
对于上述代码中与模型构建相关的代码,请查阅官方《Deep MNIST for Experts》一节的内容进行理解。在本文中,需要重点掌握的是如何将本地图片源整合成为feed_dict可接受的格式。其中最关键的是这两行
2018-08-17 15:57
libcurl是一个跨平台的网络协议库,支持http, https, ftp, gopher, telnet, dict, file, 和ldap 协议。libcurl同样支持HTTPS证书授权
2022-06-20 13:38
}] test = list( set ( test ))> >>TypeError: unhashable type : 'dict' 因为使用set去重的前提是该对象为不可变对象,而字典是可变对象,因此
2023-11-01 10:55
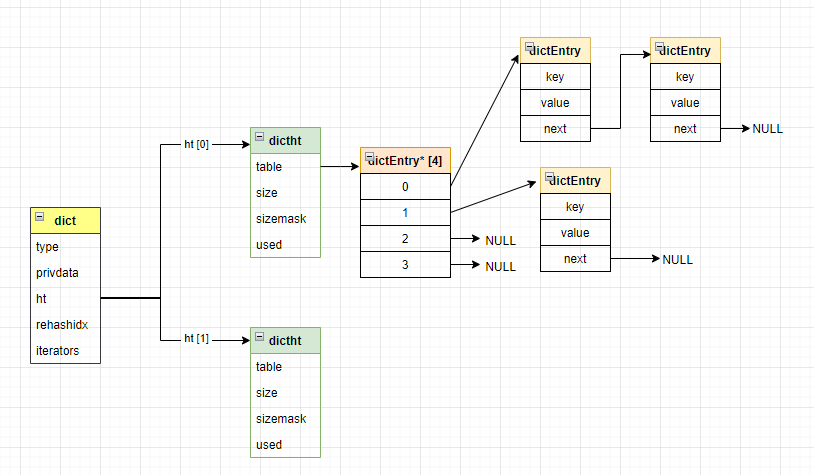
dict 中维护了一个 ht 数组,而且只有两个元素,这两个元素是其扩容的关键点,这个我们后面会讲到。 Redis中的哈希对象在以下条件时,使用ziplist编码, 哈希对象保存的所有键值的字符串长度都小于64字节 哈希对象保存的键值对数量小于512个。 否则哈希对象会使用hasht
2023-09-30 10:46