BitTorrent Speed是一款以BitTorrent代币(BTT)连接和奖励用户的软件,将与广受欢迎的μTorrent经典Windows客户端中的新下载版本整合,BitTorrent公司今日宣布了这一消息。下面就来看一下 BitTorrent Speed的新手指南。
2019-07-10 10:29
中,与没有使用PopArt的baseline agent相比,PopArt大大提高了agent的表现。无论是修剪了奖励还是没有修剪奖励,PopArt智能体在游戏中的中位数得分都高于人类中位数得分。
2018-09-16 10:04
我们的思路是,将内在奖励表示为预测agent在当前状态下的行为后果时出现的错误,即agent学习的前向动态的预测误差。我们彻底调查了54种环境中基于动力学的好奇心:这些场景包括视频游戏、物理引擎模拟和虚拟3D导航任务等,如图1所示。
2018-08-20 08:55
按照以往的做法,如果研究人员要用强化学习算法对奖励进行剪枝,以此克服奖励范围各不相同的问题,他们首先会把大的奖励设为+1,小的奖励为-1,然后对预期
2018-09-16 09:32
这个手续费是奖励给矿工的,以激励矿工继续挖矿为比特币提供足够的算力从而确保比特币网络的安全。目前矿工的主要收入是通过创造新的块(Block)来获得12.5BTC的奖励,但是这个奖励每4年减半,随着时间的推移比特币交易
2019-06-24 11:24
强化学习作为一种常用的训练智能体的方法,能够完成很多复杂的任务。在强化学习中,智能体的策略是通过将奖励函数最大化训练的。奖励在智能体之外,各个环境中的奖励各不相同。深度学习的成功大多是有密集并且有效的
2018-08-18 11:38
强化学习是一种训练主体最大化奖励的学习机制,对于目标条件下的强化学习来说可以将奖励函数设为当前状态与目标状态之间距离的反比函数,那么最大化奖励就对应着最小化与目标函数的距离。
2018-09-24 10:11
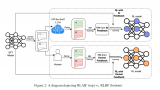
如图所示,在RLAIF中,首先使用LLM来评估给定的文本和2个候选回复,然后,这些由LLM生成的偏好数据被用来训练一个奖励模型,这个奖励模型用于强化学习,以便进一步优化LLM。
2023-09-08 16:38
作为一个简单的基线团队使用普通的策略梯度来训练一个小型的、完全连接的体系结构,将值函数基线和奖励折扣作为唯一增强。智能体不会因为实现特定的目标而获得奖励,而是只根据其生命周期 (轨迹长度) 进行优化——即在其生命周期中,每一次滴答声都会获得 1 个
2019-03-07 16:02
长期来看,我们会扩大奖励建模的规模,将其应用于人类难以评估的领域。为了做到这一点,我们需要增强用户衡量输出的能力。我们讨论了如何循环应用奖励建模:我们可以用奖励建模训练智能体,帮助用户进行评估。如果评估过程比做出动作
2018-11-24 09:31