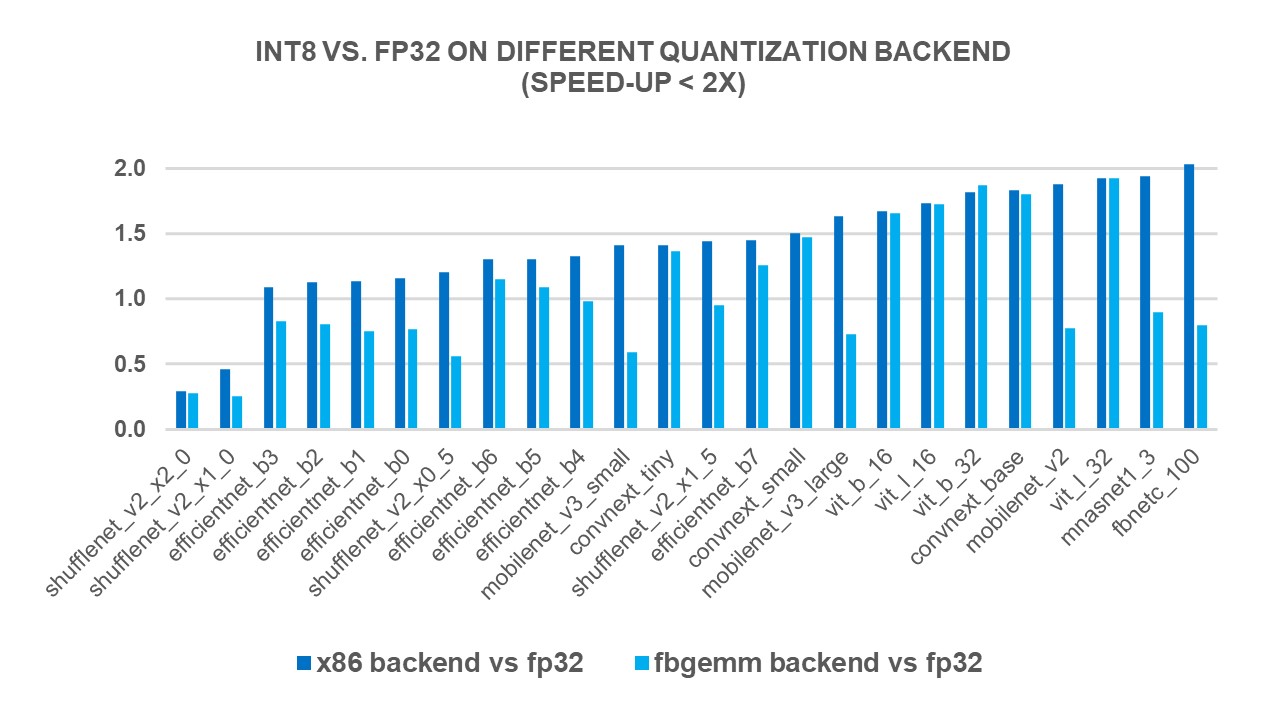
INT8量子化PyTorch x86处理器
2023-08-31 14:27
本白皮书旨在探索实现在赛灵思 DSP48E2 Slice 上的 INT8 深度学习运算,以及与其他 FPGA 的对比情况。在相同资源数量情况下,赛灵思的 DSP 架构凭借 INT8在 INT8 深度
2017-11-16 14:23
赛灵思 INT8 优化为使用深度学习推断和传统计算机视觉功能的嵌入式视觉应用提供最优异的性能和能效最出色的计算方法。与其他 FPGA/DSP 架构相比,赛灵思的集成 DSP 架构在 INT8 深度学习运算上能实现 1.75 倍的性能优势。
2017-09-22 17:27
Intel近日发布了最新版的高性能深度学习优化库DNNL 1.2,证实即将推出的全新Xe架构独立GPU的一项新技能,那就是支持Int8整数数据类型。
2020-02-04 15:31
赛灵思的 DSP 架构和库针对 INT8 运算进行了精心优化。本白皮书介绍如何使用赛灵思 16nm 和 20nm All Programmable 器件中的 DSP48E2 Slice,在共享相同内核权重的同时处理两个并行的 INT8 MACC 运算。
2019-07-29 11:19
可视化其他量化形式的engine和问题engine进行对比,我们发现是一些层的int8量化会出问题,由此找出问题量化节点解决。
2023-11-23 16:40
降低数字格式而不造成重大精度损失,要归功于按矢量缩放量化(per-vector scaled quantization,VSQ)的技术。具体来说,一个INT4数字只能精确表示从-8到7的16个整数。
2022-12-12 15:48

