
最近Intel Gaudi-3的发布,基于RoCE的Scale-UP互联,再加上Jim Keller也在谈用以太网替代NVLink。
2024-04-22 17:22

开放数据中心委员会ODCC冬季全员会议于12月4日-6日在春暖花开的昆明举行。奇异摩尔首席系统架构师朱琛作为网络工作组ETH-X超节点项目的核心成员分享了AI Networking Scale Up卡间互联的新路径解决方案并展开了相关应用分析。
2024-12-09 09:36
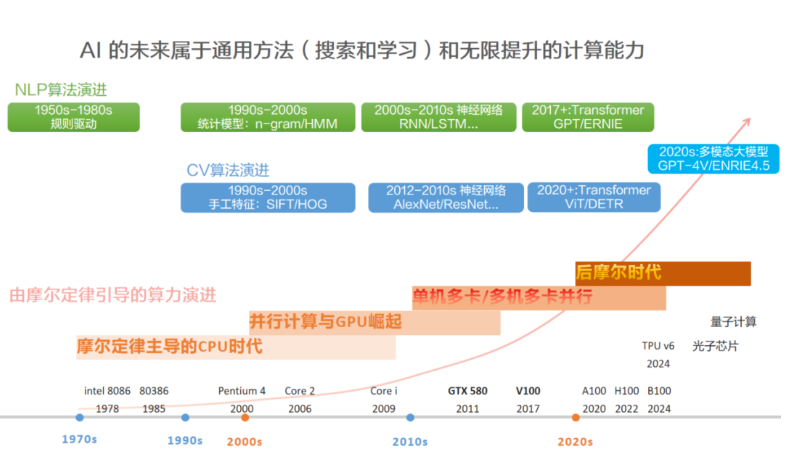
作者:算力魔方创始人/英特尔创新大使刘力 一,AI演进的核心哲学:通用方法 + 计算能力 Richard S. Sutton在《The Bitter Lesson》一文中提到,“回顾AI研究历史,得到一个AI发展的重要历史教训:利用计算能力的通用方法最终是最有效的,而且优势明显”。核心原因是摩尔定律,即单位计算成本持续指数级下降。大多数 AI 研究假设可用计算资源是固定的,所以依赖人类知识来提高性能,但长期来看,计算能力的大幅提升才是推进AI演进的关键。 《The Bitter
2025-04-09 14:31

电子发烧友网报道(文/莫婷婷)今年以来,光模块行业需求快速增长,部分海外企业持续上调资本开支指引,增加AI数据中心的建设规划,提出了对2025-2026年光模块的明确需求指引。中际旭创预计伴随AI算力需求的持续增长,光模块行业保持高景气度和高确定性,2026年仍将保持较好的行业增长趋势。 在市场增长的同时,光模块企业也迎来了业绩的快速增长。电子发烧友网统计了中际旭创、新易盛、光迅科技三家企业的财报,新易盛在前三季度实现了翻
2025-11-08 02:17

11月11日,华为在北京召开第六届创新和知识产权论坛,在论坛上,华为公布了第六届“十大发明”评选活动中获奖的创新成果,涵盖计算、鸿蒙操作系统、存储等多个面向未来的关键业务领域。
2025-11-12 14:07

我们主要探索了3D视觉中scale up模型参数量和统一模型架构的可能性。在NLP / 2D vision领域,scale up大模型(GPT-4,SAM,EVA等)已
2024-01-30 15:56
Scale-up网络是以推理的大显存并行计算流量和训练的张量并行(TP)以及专家并行(MoE)流量为主,来满足在网计算的加速需求。据相关大模型厂商介绍,对Scale-up网络规模的需求预计在未来
2024-11-18 11:14
本文详细阐述了 NVIDIA NVLink Fusion 如何借助高效可扩展的 NVIDIA NVLink scale-up 架构技术,满足日益复杂的 AI 模型不断增长的需求。
2025-09-23 14:45
在这方面,为中端存储立下新标杆的戴尔易安信PowerStore可以说是杰出代表。其同时具备的纵向扩展(Scale-up)及横向扩展(Scale-out)架构,不仅可以让升级永不停机并拥有更多弹性,还能让用户选择不同系统节点(控制器)的升级方案。
2020-12-21 15:44
技术驱动下,超节点已成为国内外构建大规模HBD域应用的关键趋势。随着千亿到万亿参数MoE大模型并行训练(尤其是专家并行和张量并行)对GPU间通信需求的激增,Scale-up超节点应运而生。
2025-07-03 11:40