
学习只使用片段作为训练信号的直接算法,从而模拟人类知道如何组合解决方法片段、但没有直接的训练信号的情况。
2018-10-26 09:34
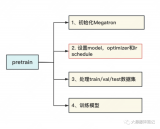
前文说过,用Megatron做分布式训练的开源大模型有很多,我们选用的是THUDM开源的CodeGeeX(代码生成式大模型,类比于openAI Codex)。选用它的原因是“完全开源”与“清晰的模型架构和预训练配置图
2023-06-07 15:08

ChatGPT对技术的影响引发了对人工智能未来的预测,尤其是多模态技术的关注。OpenAI推出了具有突破性的多模态模型GPT-4,使各个领域取得了显著的发展。 这些AI进步是通过大规模模型训练实现
2024-10-23 11:26

基于一个可伸缩的、任务无关的系统,OpenAI在一组包含不同的语言任务中获得了最优的实验结果,方法是两种现有理念的结合:迁移学习和无监督的预训练。
2018-06-13 18:00
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。
2023-05-25 17:10

专门针对序列到序列的自然语言生成任务,微软亚洲研究院提出了新的预训练方法:屏蔽序列到序列预训练(MASS: Masked Sequence to Sequence Pre-training)。MASS对句子随机屏蔽一个长度为k的连续片段,然后通过编码器-注意力-解
2019-05-11 09:34
Donkey Car是一种为模型车开源的DIY自动驾驶平台,它利用一个带有相机的树莓派单片机,让模型车可在赛道上自动驾驶,Donkey Car会学习你的驾驶方法,在训练后懂得自动驾驶。
2018-09-16 09:37
能力,逐渐成为NLP领域的研究热点。大语言模型的预训练是这一技术发展的关键步骤,它通过在海量无标签数据上进行训练,使模型学习到语言的通用知识,为后续的任务微调奠定基础。本文将深入探讨大语言模型预训练的基本原理、步骤以
2024-07-11 10:11
Whisper是OpenAI开源的,识别语音识别能力已达到人类水准自动语音识别系统。Whisper作为一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。
2025-07-17 14:55
神经网络是人工智能领域的重要分支,广泛应用于图像识别、自然语言处理、语音识别等多个领域。然而,要使神经网络在实际应用中取得良好效果,必须进行有效的训练和优化。本文将从神经网络的训练过程、常用优化算法、超参数调整以及防止过拟合等方面,详细阐述如何
2024-07-01 14:14