智能体(agent)互相争夺资源的多智能体环境是通向强人工智能(AGI)
2018-03-16 14:01
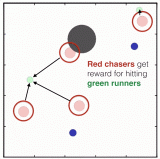
作为一个简单的基线团队使用普通的策略梯度来训练一个小型的、完全连接的体系结构,将值函数基线和奖励折扣作为唯一增强。智能体不会因为实现特定的目标而获得奖励,而是只根据其生命周期 (轨迹长度) 进行优化——即在其生命周期中,每一次滴答声都会获得 1 个奖励。
2019-03-07 16:02
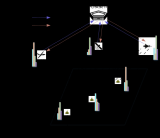
为了应对在未来复杂的战场环境下,由于通信受限等原因导致的集中式决策模式难以实施的情况,提出了一个基于多智能体深度强化学习方法的分布式作战体系任务分配算法,该算法为各作战单元均设计一个独立的策略网络
2023-05-18 16:46

随着GPT大语言模型的成功,越来越多的工作尝试使用类GPT架构的离散模型来表征驾驶场景中的交通参与者行为,从而生成多智能体仿真。这些方法展现出明显的性能优势,成为Waymo OpenSim Agents Challe
2025-04-01 14:31
信道的前提下,即展现出了类似于人的长期规划协作能力,代表了多智能体决策智能的国际最高水准,也体现了大规模算力带来的美感。
2018-06-27 12:01
由此产生的智能体,我们称之为For The Win(FTW)智能体,它学会了以非常高的标准玩CTF。最重要的是,学会的智能
2018-07-05 09:32

我们需要创建具有高度复杂性上限的开放式任务:当前的环境要么虽然复杂但过于狭窄,要么虽然开放但过于简单。持续性和大规模等属性也很关键,但是我们还需要更多的基准环境 (benchmark environments) 来量化在具有大规模和持续性条件下的学习进度。
2019-03-06 09:07

基于上述原因,需要在多体动力学模型的时域分析之前把模型处于平衡状态。注意:多体仿真模型进行频域分析之前也需要进行平衡分析,因为频域分析是在平衡位置上进行线性化。
2019-06-02 10:05
在开发RND之前,OpenAI的研究人员和加州大学伯克利分校的学者进行了合作,他们测试了在没有环境特定回报的情况下,智能体的学习情况。因为从理论上来说,好奇心提供了一种更简单的方法来教授
2018-11-05 15:15
