
针对有新类的动态数据流分类算法检测新类性能不高的问题,提出一种基于k近邻的完全随机森林算法( Kcrforest)。该算法利用动态数据流中已知类样本构建完全随机森林的完全随机树,并根据叶节点平均路径
2021-04-02 10:01
针对K近邻多标签( ML-KNN)分类算法中未考虑标签相关性的问题,提出了一种基于标签相关性的K近邻多标签分类( CML-KNN)算法。首先,计算出标签集合中每对标签间
2018-01-02 16:47
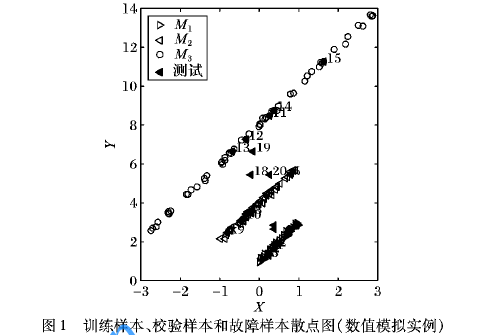
针对批次过程非线性、多模态等特征,提出一种基于判别核主元K近邻(Dis-kPCkNN)的故障检测方法。首先,在核主元分析( kPCA)中,高斯核的窗宽参数依据样本类别标签在类内窗宽和类间窗宽中判别
2019-01-22 15:54
信息采集技术日益发展导致的高维、大规模教据,给据挖掘带来了巨大挑战,针对K近邻分类算法在高维数据分类中存在效率低、时间成本高的问题,提出基于权重搜索树改进K近邻(
2021-05-08 13:57
K近邻的分类性能依赖于训练集的质量。设计高效的训练集优化算法具有重要意义。针对传统的进仳训练集优化算法效率较低、误删率较高的不足,提岀了一种遗传训练集优化算法。该算法采用基于最大汉明距离的高效
2021-05-13 14:20
针对基于七近邻的协同过滤推荐算法中存在的评分特征数据维度过高、七近邻查找速度慢,以及评分冷启动等问题,提出基于数据降维与精确欧氏局部敏感哈希( E2 LSH)的五近邻协同过滤推荐算法。首先,融合评分
2017-11-28 15:35
基于时序对齐的K近邻分类器是时间序列分类的基准算法.在实际应用中,同类复杂时间序列经常展现出不同的全局特性.由于传统时序对齐方法平等对待实例特征并忽略其局部辨别特性。因此难以准确、高效地处理此类具有
2017-12-25 16:37
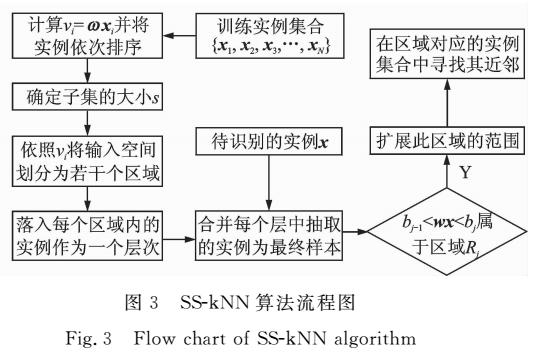
k近邻(k nearest neighbor,kNN)分类作为数据挖掘中最典型的算法之一,以较高的泛化性能以及充足的理论基础被广泛应用。然而kNN在测试时需要计算待识别实例与所有训练实例之间的距离
2018-02-27 10:46

KNN算法的主要分为3步:首先,计算待分类样本与已知类别的训练样本之间的距离或相似度,找到与待分类样本最近的k个样本,称之为待分类样本的k个近邻:其次,根据这些样本所属的类别来判断待分类样本的类别
2017-11-06 10:31

压缩模糊K-近邻( CFKNN)算法仅适用于中小数据环境,且其样例选择采用静态机制,导致算法不能对阈值进行动态调整从而选岀最优样例。为此,对 CFKNN算法进行改进,将其扩展到大规模数据环境,提出
2021-03-17 10:16