
join()方法表示为给进程添加阻塞,也就是进程运行到这里就会停滞。再没有用上join方法之前,for循环会同时创建这10个进程,但是用上了
2022-08-19 10:08
在fork-join语句块中,每个语句都是并发进程。在这个语句块中,父进程一直被阻塞,直到所有由“fork-join”产生的子进程都执行完。
2022-12-09 11:58
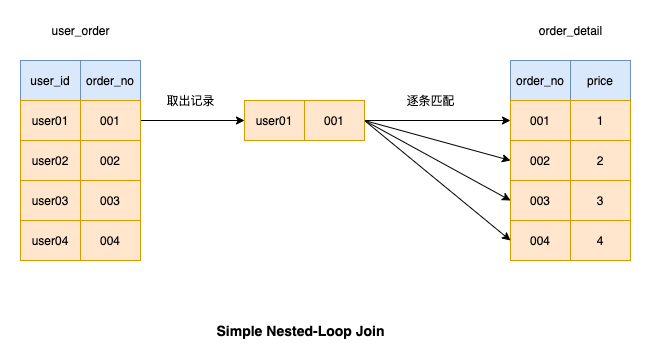
在mysql中,join 主要有Nested Loop、Hash Join、Merge Join 这三种方式,我们今天来看一下最普遍 Nested Loop 循环连接方式,主要包括三种:
2023-04-24 17:03
fork-join_any和fork-join有所不同,fork-join_any的父进程一直阻塞,直到任何一个并行的子进程结束。
2022-12-09 09:05
fork-join_none和fork-join、fork-join_any的区别一样在于进程退出机制以及对于父进程的影响。
2022-12-12 10:00
Simple Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
2022-11-17 11:56
Join作为SQL中一个重要语法特性,几乎所有稍微复杂一点的数据分析场景都离不开Join,如今Spark SQL(Dataset/DataFrame)已经成为Spark应用程序开发的主流,作为开发者
2020-09-25 11:35
对于mysql,不推荐使用子查询和join是因为本身join的效率就是硬伤,一旦数据量很大效率就很难保证,强烈推荐分别根据索引单表取数据,然后在程序里面做join,merge数据。
2023-02-23 14:07

从合并的方式看merge和join是一样的,有left/right/inner/outer,而concat只有inner/outer两种,因为merge和join参与合并的对象有左右区分,而
2018-01-06 11:55
python字符串拼接的方式 在Python的实际开发中,很多都需要用到字符串拼接,python中字符串拼接有很多,今天总结一下: 用+符号拼接 用%符号拼接 用join()方法拼接 用format
2017-12-06 10:09