该模型可以分析单词或说话风格的序列,并确定这些模式是否更容易在抑郁或抑郁的人身上表现出来,如果在新的案例中看到相同的序列模式,模型便可以根据训练的结果预测其是否有抑郁倾向。这种技术还有助于模型将整个对话视为一个整体,并分析有抑郁症和无抑郁症的人之间随着时间推移所产生的差异。
2018-09-25 11:30
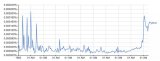
谷歌展示了每一个单词出现的百分比(某个单词在这一年出现的次数/所有单词在这一年出现的总数),这比仅仅计算原单词更有用。为了计算这个百分比,我们需要知道
2018-06-27 15:11
标识符的命名要清晰、明了, 有明确含义, 同时使用完整的单词或大家基本可以理解的缩写, 避免使人产生误解。(说明: 较短的单词可通过去掉“元音”形成缩写; 较长的单词可取单词
2023-05-29 10:14
文本压缩器就以这种方式工作。例如,GitHub拥有一个广泛使用的单词列表,可用它来为每个单词分配数字索引。因此,要将一段文本编码为二进制,需要将每个单词替换为其数字索引——比如GitHub的列表中用
2018-12-12 13:42
对于IDF而言,长文档包含的单词更多,因此更容易出现各种单词。因此,IDF相等的情况下,经常出现在短文档中的单词,信息量比经常出现在长文档中的单词要高。例如,假设100
2018-06-25 14:50

这下空白处改填的内容完全变了。这时’red’这个词最有可能适合这个位置。从这个例子中我们能学到,一个单词的前后词语都带信息价值。事实证明,我们需要考虑两个方向的单词(目标单词的左侧
2019-04-10 17:48
首先我们对比自然语言处理和图像处理:NLP 最基本的数据元素是单词,每个单词有一定的含义,可能指代某个实体;
2022-10-20 10:03
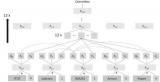
Transofrmer一个常见的自监督目标是遮罩文本中出现的单词,将该位置的query, key和value向量与其他单词进行比较,计算出注意力权重并加权平均,再通过全连接层、归一化层和残差连接来产生新的单词向量,再
2023-09-07 16:04
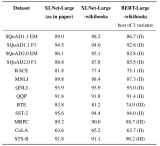
训练语料库:Wikipedia + BooksCorpus,在处理Wikipedia时使用了与BERT repo相同的工具,但出于某种原因,我们的Wiki语料库仅有20亿单词,BERT使用了25亿单词,因此XLNet的训练数据略少于BERT。
2019-07-27 07:14
输入张量让我们能够以索引序列的形式输入多个句子。这个方向是对的,但这些索引并没有保留什么信息。索引54代表的单词,和索引55代表的单词可能全无关系。基于这些索引数字进行计算没什么意义。这些索引需要以其他格式表示,让模型可以计算一些有意义的东西。一种更好的表示
2018-11-05 15:23