
TVM主要的编译过程如下图:Import:将tensorflow,onnx,pytorch等构建的深度学习模型导入,转化成TVM的中间层表示IR。Lower:将高层IR表示转化成低阶TIR表示。Codegen:内存分
2022-02-08 14:51
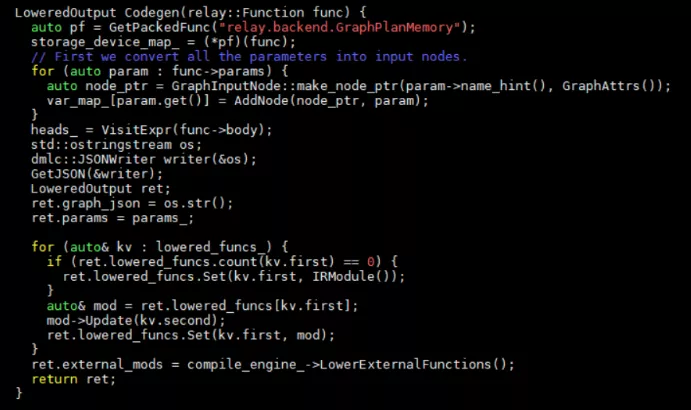
接着上一章继续深入代码,在BuildRelay中会调用Codegen函数。这个函数实现在src/relay/backend/graph_runtime_codegen.cc中。Codegen实现了内存的分配,IR节点
2022-02-08 16:02
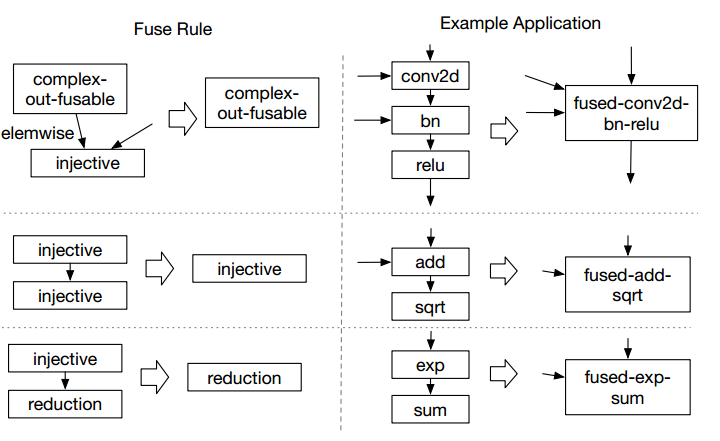
算符融合将多个计算单元揉进一个计算核中进行,减少了中间数据的搬移,节省了计算时间。TVM中将计算算符分成四种: 1 injective。一一映射函数,比如加法,点乘等。 2 reduction
2022-02-08 14:44
Lower操作完成从高级算子(relay)到低级算子(TOPI)的转化。Lower开始于以下代码(src/relay/backend/graph_runtime_codegen.cc)
2022-08-02 10:16
TVM与现有的开发生态系统无缝连接,并支持 DPoS。 TVM最初与 EVM 环境兼容,因此开发人员可以使用Solidity和其他语言在 Remix 环境中开发,调试和编译智能合约,而不是学习新
2019-05-15 09:46
为了因应全球朝向节能的趋势,X-FAB Silicon Foundries日前发表XU035工艺,一个针对超高压与消费性市场的CMOS工艺,消费性市场例如LED照明、手机充电器等电源转换与控制的应用。XU035制程提
2012-05-25 09:33
威联通科技(QNAP Systems, Inc.)宣布推出全新机架式TS-x32XU NAS 系列,共有4硬盘槽TS-432XU、8硬盘槽TS-832XU及12硬盘槽TS-1232
2018-06-26 09:07
Mentor Graphics Corp.日前宣布推出Capital Harness TVM,这是Capital软件套件中的最新工具。Capital Harness TVM是Capital工具套件的组成部分,该套件是一个面向汽车、航空和国防行业的强大的电气系统和线
2013-05-15 23:40

Pass是TVM中基于relay IR进行的优化,目的是去除冗余算子,进行硬件友好的算子转换,最终能够提高硬件运行效率。由tensorflow等深度学习框架生成的图机构中,含有很多可以优化的算子
2022-08-02 09:43
