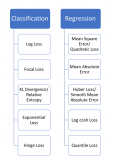
所有的机器学习算法都或多或少的依赖于对目标函数最大化或者最小化的过程。我们常常将最小化的函数称为损失函数,它主要用于衡量
2018-06-13 17:53
对于许多机器学习算法来说,最终要解决的问题往往是最小化一个函数,我们通常称这个函数叫损失函数。在神经网络里面同样如此,
2017-11-30 16:09
这个损失函数是合理的,因为当 $t$ 接近 0 时,$-log(t)$ 变得非常大,所以如果模型估计一个正例概率接近于 0,那么损失函数将会很大,同时如果模型估计一个负
2018-06-29 15:02
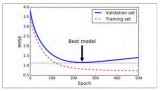
神经网络优化算法是深度学习领域中的核心技术之一,旨在通过调整网络中的参数(如权重和偏差)来最小化损失函数,从而提高模型的性能和效率。本文将详细探讨神经网络
2024-07-03 16:01
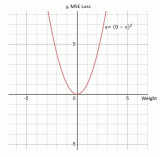
从上面阐释的步骤可以看出,神经网络中的权重由损失函数的导数而不是损失函数本身来进行更新或反向传播。因此,损失
2019-05-05 11:42

提升树利用加法模型与前向分步算法实现学习的优化过程,当损失函数为平方损失和指数损
2019-09-23 08:52
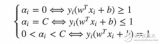
在SMO算法中,我们每次需要选取一对α来进行优化,通过启发式的选取我们可以更高效的选取待优化的变量使得目标函数下降的最快。
2017-10-18 14:21

在有些情况下,我们知道目标函数的表达形式,但因为目标函数形式复杂不方便对变量直接求导。这个时候可以尝试找到目标函数的一个下界函数,通过对下界
2019-07-13 08:09
损失函数通过torch.nn包实现基本用法 criterion = LossCriterion() #构造函数有自己的参数loss = criterion(x, y) #调用标准时也有参数19种
2019-09-14 10:34

编译器如gcc,可以指定不同的优化参数,在某些条件下,有些函数可能会被优化掉。
2020-06-22 14:58