1. 设计与构建质量 Llama 3的设计延续了其前代产品的简洁风格,同时在细节上进行了优化。机身采用了轻质材料,使得整体重量得到了有效控制,便于携带。此外,Llama 3
2024-10-27 14:30
Meta 发布的 LLaMA 2,是新的 sota 开源大型语言模型 (LLM)。LLaMA 2 代表着 LLaMA 的下一代版本,并且具有商业许可证。
2024-02-21 16:00
在人工智能领域,大型语言模型(LLMs)的发展速度令人震惊。2024年4月18日,Meta正式开源了LLama系列的新一代大模型Llama3,在这一领域中树立了新的里程碑。
2024-04-26 09:42
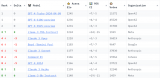
Llama3 是Meta最新发布的开源大语言模型(LLM), 当前已开源8B和70B参数量的预训练模型权重,并支持指令微调。
2024-05-10 10:34
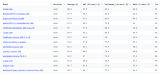
训练),并且和Vision结合的大模型也逐渐多了起来。所以怎么部署大模型是一个 超级重要的工程问题 ,很多公司也在紧锣密鼓的搞着。 目前效果最好讨论最多的开源实现就是LLAMA,所以我这里讨论的也是基于 LLAMA的魔改部署 。 基于
2023-05-23 15:08
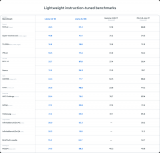
前面我们分享了《三步完成Llama3在算力魔方的本地量化和部署》。2024年9月25日,Meta又发布了Llama3.2:一个多语言大型语言模型(LLMs)的集合。
2024-10-12 09:39
这是一组由 Meta 开源的大型语言模型,共有 7B、13B、33B、65B 四种版本。其中,LLaMA-13B 在大多数数据集上超过了 GPT-3(175B),LLaMA-65B 达到了和 Chinchilla-7
2023-06-11 11:24
LLama.cpp 支持x86,arm,gpu的编译。
2024-01-22 09:10

随着 Llama 2 的逐渐走红,大家对它的二次开发开始流行起来。前几天,OpenAI 科学家 Karpathy 利用周末时间开发了一个明星项目 llama2.c,借助 GPT-4,该项目仅用
2023-08-02 16:25

从 GPT-3,Gopher 到 LLaMA,大模型有更好的性能已成为业界的共识。但相比之下,单个 GPU 的显存大小却增长缓慢,这让显存成为了大模型训练的主要瓶颈,如何在有限的 GPU 内存下训练大模型成为了一个重要的难题。
2023-09-11 16:08