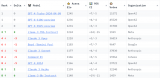
Llama3 是Meta最新发布的开源大语言模型(LLM), 当前已开源8B和70B参数量的预训练模型权重,并支持指令微调。
2024-05-10 10:34
训练),并且和Vision结合的大模型也逐渐多了起来。所以怎么部署大模型是一个 超级重要的工程问题 ,很多公司也在紧锣密鼓的搞着。 目前效果最好讨论最多的开源实现就是LLAMA
2023-05-23 15:08

而这一切的背后,是一项名为Sorted Fine-Tuning(SoFT)的新训练技术。SoFT让我们可以在一个训练周期内产出多个子模型,无需任何额外的预训练步骤。此外
2023-09-26 16:26
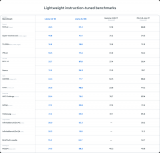
前面我们分享了《三步完成Llama3在算力魔方的本地量化和部署》。2024年9月25日,Meta又发布了Llama3.2:一个多语言大型语言模型(LLMs)的集合。
2024-10-12 09:39
Meta 发布的 LLaMA 2,是新的 sota 开源大型语言模型 (LLM)。LLaMA 2 代表着 LLaMA 的下一代版本,并且具有商业许可证。
2024-02-21 16:00
1. 设计与构建质量 Llama 3的设计延续了其前代产品的简洁风格,同时在细节上进行了优化。机身采用了轻质材料,使得整体重量得到了有效控制,便于携带。此外,Llama 3
2024-10-27 14:30
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用
2023-05-25 17:10
能力,逐渐成为NLP领域的研究热点。大语言模型的预训练是这一技术发展的关键步骤,它通过在海量无标签数据上进行训练,使模型学习到语言的通用知识,为后续的任务微调奠定基础。
2024-07-11 10:11
预训练模型(Pre-trained Model)是深度学习和机器学习领域中的一个重要概念,尤其是在自然语言处理(NLP)和计算机视觉(CV)等领域中得到了广泛应用。预训练模型
2024-07-03 18:20
深度学习模型训练是一个复杂且关键的过程,它涉及大量的数据、计算资源和精心设计的算法。训练一个深度学习模型,本质上是通过优化算法调整
2024-07-01 16:13