
作为MC评测室的“常驻嘉宾”,影驰星曜系列的设计对于我们来说可谓烂熟于心,而影驰GEFORCE RTX 4070 TI SUPER星曜OC在外观设计方面依然沿袭了星曜系列的设计,其差异与它的“姐姐们”相差不会过于悬殊,主要还是在尺寸方面。
2024-01-29 10:49

TensorFlow今天正式发布了1.5.0版本,支持CUDA 9和cuDNN 7,进一步提速。并且,从1.6版本开始,预编译二进制文件将使用AVX指令,这可能会破坏老式CPU上的TF。
2018-01-29 15:02

Tensor Core所运行的张量应位于存储器的channel-interleaved型数据布局(数量-高度-宽度-通道数,通常称为NHWC),以实现最佳性能。训练框架预期的内存布局是通道主序的数据布局(数量-通道数-宽度-高度,通常称为NCHW)。因此,cuDNN库执行NCHW和NHWC之间的张量转置操作,如图3所示。如前所述,由于如今卷积本身如此之快,因此这些转置显然会占运行时间的一部分。
2018-05-21 17:35
那么如何选择适合你的 GPU 呢?本文作者 Tim Dettmers 是瑞士卢加诺大学信息学硕士,热衷于开发自己的 GPU 集群和算法来加速深度学习。这篇文章深入研究这个问题,并提供建议,帮你做出最合适的选择。
2018-08-24 08:49
仅通过添加几行代码,TensorFlow、PyTorch和MXNet中的自动混合精确功能就能助力深度学习研究人员和工程师基于NVIDIA Volta和Turing GPU实现高达3倍的AI训练加速。
2019-04-03 11:31

最先 Tesla 架构,分别经过 Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere至发展为今天的 Hopper 架构。
2023-05-15 11:16
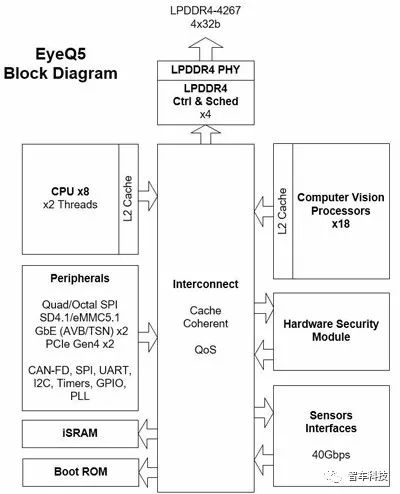
主要来自于4颗处理器-2颗为以NVIDIA目前最新GPU架构「Volta」为核心的SoC「Xavier」、以及另外2颗为车用机械视觉与深度学习所准备的专用GPU。
2018-06-03 10:37
现在我们假设在一个英伟达Volta V100 GPU上用100%的计算力,训练将需要多长时间。网络在一张32×32×3的CIFAR10图像上进行前向和后向传递时需要大约2.8×109FLOPs。假设
2018-11-12 09:35
以RedmiBook 16为例,它的锐龙版和酷睿版之间只是处理器分别是锐龙5 4500U/锐龙7 4700U,i5-1035G/i7-1065G7,差异只是后者增加可了额外的Geforce MX350独显,内部的热管多了一根,内存频率提升。
2020-09-04 15:10
借助 R515 驱动程序,NVIDIA 于 2022 年 5 月发布了一套开源的 Linux GPU 内核模块,该模块采用双许可证,即 GPL 和 MIT 许可。初始版本主要面向数据中心计算 GPU,而 GeForce 和工作站 GPU 则处于 Alpha 状态。
2024-07-25 09:56