
专门针对序列到序列的自然语言生成任务,微软亚洲研究院提出了新的预训练方法:屏蔽序列到序列预训练(MASS: Masked Sequence to Sequence Pre-training)。MASS对句子随机屏蔽一个长度为k的连续片段,然后通过编码器-注意力-解
2019-05-11 09:34
在使用FPGA的时候,有些IP核是需要申请后才能使用的,本文介绍如何申请xilinx IP核的license。
2024-10-25 16:48
预训练模型(Pre-trained Model)是深度学习和机器学习领域中的一个重要概念,尤其是在自然语言处理(NLP)和计算机视觉(CV)等领域中得到了广泛应用。预训练模型指的是在大型数据集上预先
2024-07-03 18:20
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。
2023-05-25 17:10
能力,逐渐成为NLP领域的研究热点。大语言模型的预训练是这一技术发展的关键步骤,它通过在海量无标签数据上进行训练,使模型学习到语言的通用知识,为后续的任务微调奠定基础。本文将深入探讨大语言模型预训练的基本原理、步骤以及面临的挑战。
2024-07-11 10:11
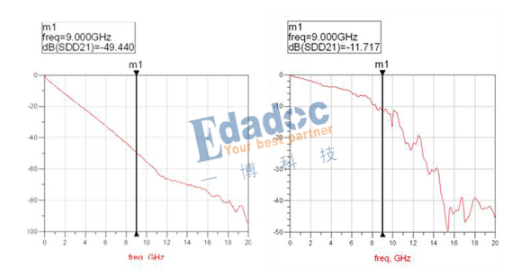
在这对于预加重与均衡的优缺点稍微做一下总结: 1.预加重实现起来比均衡要简单,功耗低一些。 2.预加重增益不能做太大,一个1.1Vpp的输出不可能预加重后转化为5Vpp
2021-04-13 17:34
预训练和迁移学习是深度学习和机器学习领域中的两个重要概念,它们在提高模型性能、减少训练时间和降低对数据量的需求方面发挥着关键作用。本文将从定义、原理、应用、区别和联系等方面详细探讨预训练和迁移学习。
2024-07-11 10:12
预训练通常被用于自然语言处理以及计算机视觉领域,以增强主干网络的特征提取能力,达到加速训练和提高模型泛化性能的目的。该方法亦可以用于场景文本检测当中,如最早的使用ImageNet预训练模型初始化参数
2022-08-08 15:33
NLP中,预训练大模型Finetune是一种非常常见的解决问题的范式。利用在海量文本上预训练得到的Bert、GPT等模型,在下游不同任务上分别进行finetune,得到下游任务的模型。然而,这种方式
2022-03-21 15:33
问题描述: 在Xilinx中的很多IP和开发工具,都是需要付费才能购买正版的license的。不过XIlinx一般也提供有评估版本的license,可以供大部分客户来免费申请。下面就简单介绍下评估license的申请途径和方法。
2018-07-04 09:46