
机器学习算法是数据挖掘、数据能力分析和数学建模必不可少的一部分,而随机森林算法和决策树算法是其中较为常用的两种
2023-09-21 11:17
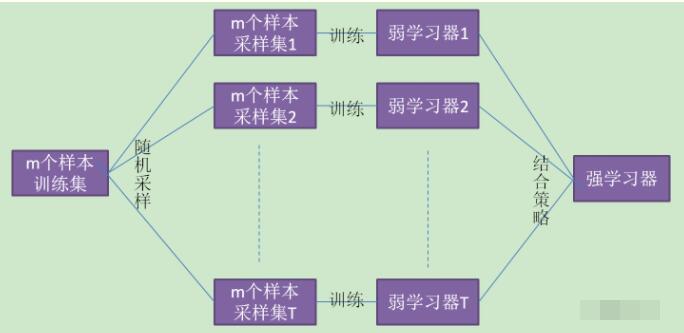
集成学习有两个流派,一个是boosting,特点是各个弱学习器之间有依赖关系;一个是bagging,特点是各个弱学习器之间没依赖关系,可以并行拟合。
2020-12-09 13:58
随机森林是一种灵活且易于使用的机器学习算法,即便没有超参数调优,也可以在大多数情况下得到很好的结果。它也是最常用的算法之一,因为它很简易,既可用于分类也能用于回归任务。
2018-03-14 16:10
随机森林是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表
2022-10-10 17:14
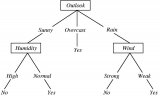
我们知道决策树容易过拟合。换句话说,单个决策树可以很好地找到特定问题的解决方案,但如果应用于以前从未见过的问题则非常糟糕。俗话说三个臭皮匠赛过诸葛亮,随机森林就利用了多个决策树,来应对多种不同场景。
2019-04-19 14:38
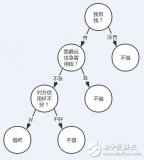
为什么要引入随机森林呢。我们知道,同一批数据,我们只能产生一颗决策树,这个变化就比较单一了,这就有了集成学习的概念。
2017-10-18 17:47

随机森林由Breiman提出的一种分类算法,它使用Bootstrap重采样技术,从原始训练样本集中有放回的重复随机抽取n个样本生成新的样本集合,以此作为训练集来训练决策
2019-09-23 09:58

本章讨论的最后一个集成方法叫做 Stacking(stacked generalization 的缩写)。这个算法基于一个简单的想法:不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,我们
2018-07-27 17:40

、信息加密和系统测试等诸多领域中都有着 广泛的应用。在自适应光学SPGD 算法中,伪随机序列亦有相当重要的作用。
2018-07-16 09:57
令人惊奇的是这种投票分类器得出的结果经常会比集成中最好的一个分类器结果更好。事实上,即使每一个分类器都是一个弱学习器(意味着它们也就比瞎猜好点),集成后仍然是一个强学习器(高准确率),只要有足够数量的弱学习者,他们就足够多样化。
2018-07-17 17:07