机器学习算法是数据挖掘、数据能力分析和数学建模必不可少的一部分,而随机森林算法和决策树算法是其中较为常用的两种
2023-09-21 11:17
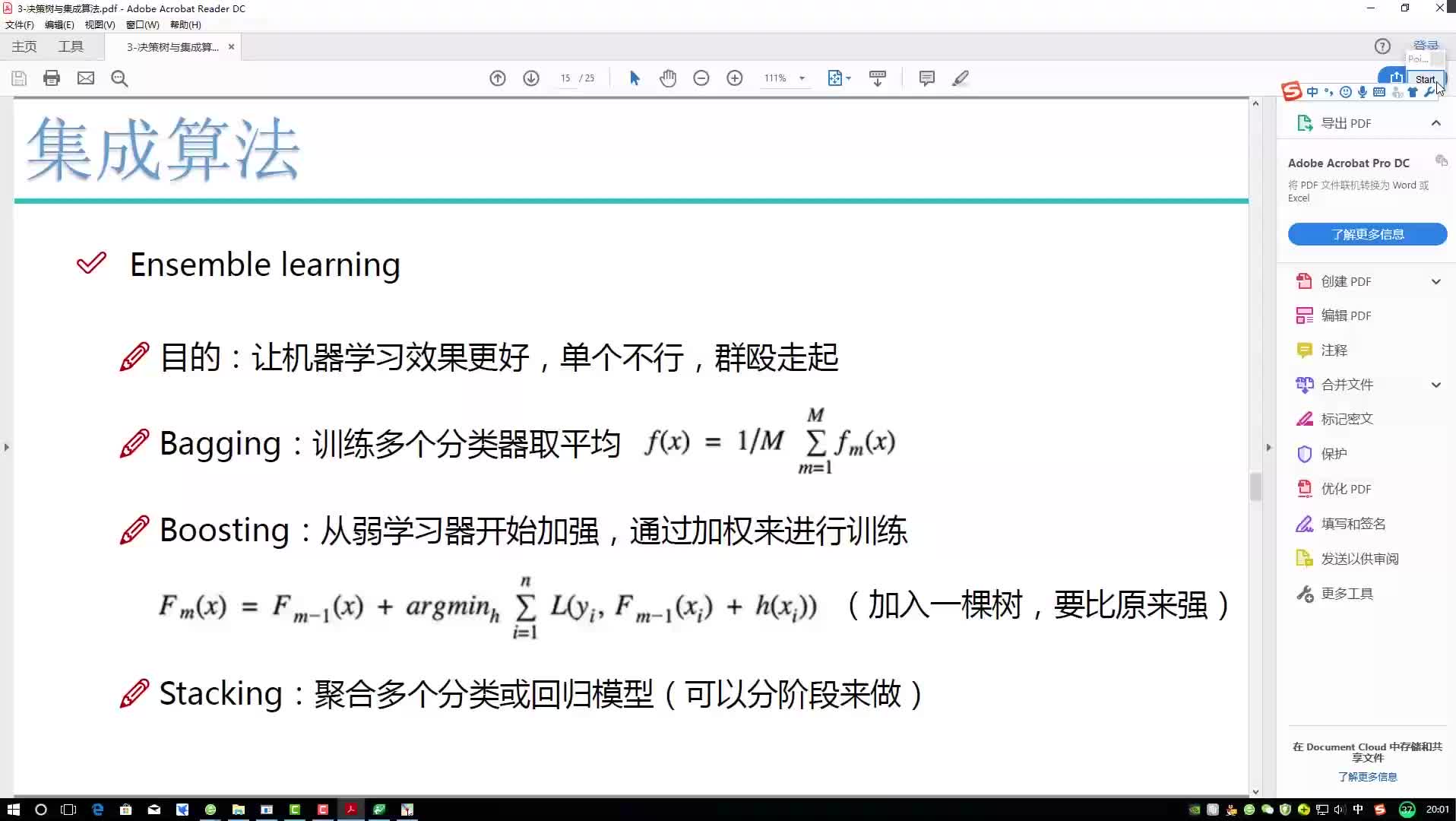
集成学习有两个流派,一个是boosting,特点是各个弱学习器之间有依赖关系;一个是bagging,特点是各个弱学习器之间没依赖关系,可以并行拟合。
2020-12-09 13:58

针对有新类的动态数据流分类算法检测新类性能不高的问题,提出一种基于k近邻的完全随机森林算法( Kcrforest)。该算法
2021-04-02 10:01
数据挖掘中的隐私保护问题是目前信息安全领域的研究热点之一。针对隐私保护要求下的分类问题,提出一种面向差分隐私保护的随机森林算法 REDPP-Gini。将随机
2021-05-12 14:14

用于销售预测的历史数据存在稀疏性与波动性等特点,当预测周期较长时,传统统计学或者机器学习领域预测算法的预测效果较差。为此,利用随机森林的集成思想与训练数据集的随机分割重
2021-03-16 11:37
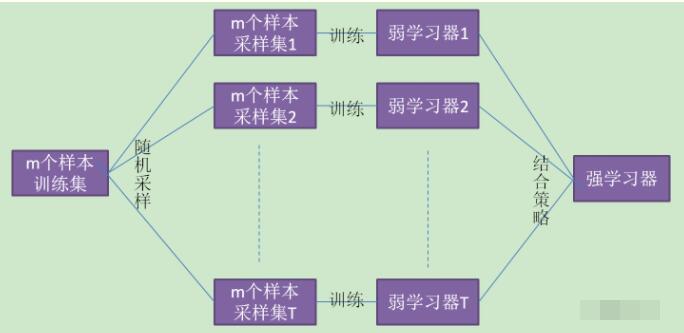
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
2023-05-15 09:46
几个月前,我在悉尼参加了一个会议。会上fast.ai向我介绍了一门在线机器学习课程,那时候我根本没注意。这周在Kaggle竞赛寻找提高分数的方法时,我又遇到了这门课程。我决定试一试。
2020-05-05 08:50
本次主题是随机森林,杰里米(讲师)提供了一些基本信息以及使用Jupyter Notebook的提示和技巧。 Jeremy谈到的一些重要的事情是,数据科学并不等同于软件工程。 在数据科学中,我们做
2020-09-29 15:34
随机森林是一种灵活且易于使用的机器学习算法,即便没有超参数调优,也可以在大多数情况下得到很好的结果。它也是最常用的算法之一,因为它很简易,既可用于分类也能用于回归任务。
2018-03-14 16:10