最近一段时间,基于Transformer网络结构的视觉大模型呈现出爆发式增长,继Segment Anything(SAM)之后,Meta AI再次发布重量级开源项目——DINOv2。DINOv2可以抽取到强大的图像特征,且在下游任务上不需要微调,这使得它适合作为许
2023-06-30 10:07
几天前,OpenAI「超级对齐」(Superalignment)团队发布了成立以来的首篇论文,声称开辟了对超人类模型进行实证对齐的新研究方向。GPT-2能监督GPT-4,Ilya带头OpenAI超级对齐首篇论文来了:AI对齐AI取得实证结果
2024-01-08 11:07

对此,ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作模型,只用单机就可以训练。使用简单、少量的微调就可以把 V
2024-01-23 16:02
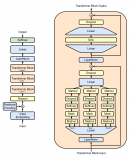
机器学习模型依赖于批处理(Batching)来提高推断吞吐量,尤其是对于 ResNet 和 DenseNet 等较小的计算机视觉模型。
2023-12-18 15:52
正确地理解它们都是水果。计算机视觉的模型可以区分香蕉和猕猴桃,但这些模型并不是对更抽象的知识进行编码,即:它们都是水果。”
2018-07-31 09:49
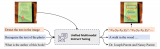
如上图所示,UniDoc基于预训练的视觉大模型及大语言模型,将文字的检测、识别、spotting(图中未画出)、多模态理解等四个任务,通过多模态指令微调的方式,统一到一个框架中。具体地,输入一张图像以及一条指令(可以
2023-08-31 15:29

在Github已经获得2.4K+次星标,在Twitter、PaperswithCode等平台也受到了广泛关注。 相关论文预印本现已发表。 以下内容由投稿者提供 视觉基础模型 SAM[1]在许多计算机视觉
2023-07-03 17:06

视觉语言模型(VLM)是一种多模态、生成式 AI 模型,能够理解和处理视频、图像和文本。
2025-02-12 11:13

SAM被认为是里程碑式的视觉基础模型,它可以通过各种用户交互提示来引导图像中的任何对象的分割。SAM利用在广泛的SA-1B数据集上训练的Transformer模型,使其能够熟练处理各种场景和对象。
2023-06-28 15:08
本文提出了一种将视觉语言模型(VLM)转换为端到端导航策略的具体框架。不依赖于感知、规划和控制之间的分离,而是使用VLM在一步中直接选择动作。惊讶的是,我们发现VLM可以作为一种无需任何微调或导航数据的端到端策略来使用。这使得该方法具有开放性和可适用于任何下游导航
2024-11-22 09:42