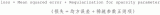
稀疏自编码器(又称稀疏自动编码机)中,重构误差中添加了一个稀疏惩罚,用来限定任何时刻的隐藏层中并不是所有单元都被激活。如果 m 是输入模式的总数,那么可以定义一个参数 ρ_hat,用来表示每个隐藏层单元的行为(平均
2019-06-11 16:45
2022 年 5 月,科学家们发布了一张图像,尽管它的视觉简单,但让所有看过它的人都感到惊讶:这是第一张黑洞的“真实”图像。
2022-09-05 10:40
学习带来的红利了么?近日来自卡内基梅隆大学、亚马逊研究院、加州理工学院的研究员,在人工智能顶级会议 UAI 上阐述了多种方法,尝试缓解甚至解决数据稀疏对深度学习的影响。
2018-08-12 11:49

作者引入了一种方法,可以仅使用单个宽基线立体图像对生成新视角。在这种具有挑战性的情况下,3D场景点只被正常观察一次,需要基于先验进行场景几何和外观的重建。作者发现从稀疏观测中生成新视角的现有方法因
2023-06-13 09:29
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些ρˆρ^ 和 ρρ 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种(KL散度)
2019-06-11 16:28
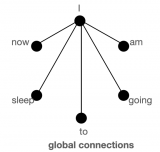
RoBERTa 架构的 BigBird 模型现已集成入 transformers 中。本文的目的是让读者 深入 了解 BigBird 的实现,并让读者能在 transformers 中轻松使用 BigBird。但是,在更深入之前,一定记住 BigBird 注意力只是 BERT 完全注意力的一个近似,因此我们并不纠结于让它比 BERT 完全注意力 更好,而是致力于让它更有效率。
2023-11-29 11:02
上图中间是第一种步进注意力的版本,可以粗略的理解为每一个位置需要注意它所在的行和列;另一种固定注意力的方式则尝试着从固定的列和元素中进行处理,这种方式对于非二维结构的数据有着很好的效果。
2019-04-28 09:41
极致的感知性能与极简的感知pipeline一直是牵引我们持续向前的目标。为了实现该目标,打造一个性能优异的端到端感知模型是重中之重,充分发挥深度神经网络+数据闭环的作用,才能打破当前感知系统的性能上限,解决更多的corner case,让系统更加鲁棒。因此,在Sparse4D-v3中,我们主要做了两部分工作,其一是进一步提升模型的检测性能,另一是将Sparse4D拓展为一个端到端跟踪模型,实现多视角视频到目标运动轨迹端到端感知。
2024-01-23 10:20
在进行分割之前,需要从扫描的点云数据中移除地面。这种地面移除的方法,只是把低于车辆高度的3D点移除。这种方法在简单的场景中起作用,但是如果在车辆的俯仰或者侧倾角不等于零或者地面不是完美的平面。则会失败。但是可以使用RANSAC的平面拟合的方法改善情况。
2018-11-16 16:45
让儿童(和成年人)整理东西已经是件难事了,但是想让AI像人一样整理东西是个不小的挑战。一些视觉运动的核心技能
2018-03-17 10:51