
这篇文章描述了两种不同的加速矩阵乘法的方法。第一种方法使用 Numba 编译器来减少 Python 代码中与循环相关的开销。第二种方法使用 CUDA 并行化矩阵乘法
2022-04-24 17:04
单精度矩阵乘法(SGEMM)几乎是每一位学习 CUDA 的同学绕不开的案例,这个经典的计算密集型案例可以很好地展示 GPU 编程中常用的优化技巧。本文将详细介绍 CUDA SGEMM 的优化手段
2022-09-28 09:46
一致,均为3x3方阵。激活区域与滤波器对应系数相乘并相加即获得对应的输出(这里是矩阵元素对应相乘相加,不是矩阵乘法)。紧接着,滑窗右移一格,得到新的激活区域,再次与滤波器对应元素相乘相加获得第2个输出。这里滑窗的步进
2021-03-03 14:49
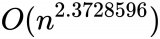
n阶矩阵乘法最优解的时间复杂度再次被突破,达到了 。 按定义直接算的话,时间复杂度是O(n³)。 光这么说可能不太直观,从图上可以看出,n足够大时优化后的算法就开始表现出明显优势。 矩阵
2021-06-24 17:36
Adreno GPU架构,用于计算和加速重要线性代数算法,包括GPU上的矩阵乘法。 由于近来依赖于卷积的深度学习引起广泛关注,矩阵乘法(MM)运算也在GPU上变得流行
2018-09-18 19:15
NVIDIA Hopper GPU 上的新 cuBLAS 12.0 功能和矩阵乘法性能
2023-07-05 16:30

本篇文章是GEMM优化的第一个部分,在这篇文章中,只说优化思路和分析。
2023-05-25 09:03
CUTLASS 实现了高性能卷积(隐式 GEMM )。隐式 GEMM 是作为 GEMM 的卷积运算的公式。这允许 Cutslass 通过重用高度优化的 warp-wide GEMM 组件和以下组件来构建卷积。
2022-04-15 10:03
矩阵乘法:使用英特尔®数学核心函数库和C++测试英特尔®ComposerXE 2015
2018-11-12 06:42
我们使用英特尔®数学核心函数库(MKL)在Linux *上优化了三重嵌套循环矩阵乘法的版本。
2018-11-07 06:04