
电子发烧友网站提供《FPGA加速神经网络的矩阵乘法.pdf》资料免费下载
2023-09-15 14:50

这篇文章描述了两种不同的加速矩阵乘法的方法。第一种方法使用 Numba 编译器来减少 Python 代码中与循环相关的开销。第二种方法使用 CUDA 并行化矩阵乘法
2022-04-24 17:04
单精度矩阵乘法(SGEMM)几乎是每一位学习 CUDA 的同学绕不开的案例,这个经典的计算密集型案例可以很好地展示 GPU 编程中常用的优化技巧。本文将详细介绍 CUDA SGEMM 的优化手段
2022-09-28 09:46
一致,均为3x3方阵。激活区域与滤波器对应系数相乘并相加即获得对应的输出(这里是矩阵元素对应相乘相加,不是矩阵乘法)。紧接着,滑窗右移一格,得到新的激活区域,再次与滤波器对应元素相乘相加获得第2个输出。这里滑窗的步进
2021-03-03 14:49
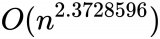
n阶矩阵乘法最优解的时间复杂度再次被突破,达到了 。 按定义直接算的话,时间复杂度是O(n³)。 光这么说可能不太直观,从图上可以看出,n足够大时优化后的算法就开始表现出明显优势。 矩阵
2021-06-24 17:36
为满足深度学习推理中对不同规模矩阵乘法的计算需求,提出一种基于 Zynq soc平台的整数矩阵乘法加速器。采用基于总线广播的并行结构,充分利用片上数据的重用性并最小化中
2021-05-25 16:26
Adreno GPU架构,用于计算和加速重要线性代数算法,包括GPU上的矩阵乘法。 由于近来依赖于卷积的深度学习引起广泛关注,矩阵乘法(MM)运算也在GPU上变得流行
2018-09-18 19:15
请问nice接口可以运算矩阵的乘法吗,例程中给了加法的运算,但是过程我没太看明白, 特别是fun3和fun7的定义,还有寄存器的使用, 比如例程中: __STATIC_FORCEINLINE
2023-08-16 08:00
本代码于Xilinx的FPGA芯片 Spartan-6 XC6SLX45-CSG324-3上实现。[code]library ieee; use ieee.std_logic_1164.all; use ieee.numeric_std.all; use IEEE.STD_LOGIC_UNSIGNED.ALL; -- Required entity declaration entity IntMatMulCore isport(Reset, Clock,WriteEnable, BufferSel:in std_logic;WriteAddress: in std_logic_vector (9 downto 0);WriteData:in std_logic_vector (15 downto 0);ReadAddress:in std_logic_vector (9 downto 0);ReadEnable:in std_logic;ReadData:out std_logic_vector (63 downto 0);DataReady:out std_logic); end IntMatMulCore; architecture IntMatMulCore_arch of IntMatMulCore is -- fpga4student.com FPGA projects, Verilog projects, VHDL projects COMPONENT dpram1024x16PORT (clka : IN STD_LOGIC;wea : IN STD_LOGIC_VECTOR(0 DOWNTO 0);addra : IN STD_LOGIC_VECTOR(9 DOWNTO 0);dina : IN STD_LOGIC_VECTOR(15 DOWNTO 0);clkb : IN STD_LOGIC; enb : IN STD_LOGIC;addrb : IN STD_LOGIC_VECTOR(9 DOWNTO 0);doutb : OUT STD_LOGIC_VECTOR(15 DOWNTO 0)); END COMPONENT; COMPONENT dpram1024x64PORT (clka : IN STD_LOGIC;wea : IN STD_LOGIC_VECTOR(0 DOWNTO 0);addra : IN STD_LOGIC_VECTOR(9 DOWNTO 0);dina : IN STD_LOGIC_VECTOR(63 DOWNTO 0);clkb : IN STD_LOGIC;enb : IN STD_LOGIC;addrb : IN STD_LOGIC_VECTOR(9 DOWNTO 0);doutb : OUT STD_LOGIC_VECTOR(63 DOWNTO 0)); END COMPONENT; typestateType is (stIdle, stWriteBufferA, stWriteBufferB, stReadBufferAB, stSaveData, stWriteBufferC, stComplete); signal presState: stateType; signal nextState: stateType; signal iReadEnableAB, iCountReset,iCountEnable, iCountEnableAB,iCountResetAB: std_logic; signal iWriteEnableA, iWriteEnableB, iWriteEnableC: std_logic_vector(0 downto 0); signal iReadDataA, iReadDataB: std_logic_vector (15 downto 0); signal iWriteDataC: std_logic_vector (63 downto 0); signal iCount, iReadAddrA, iReadAddrB,iRowA : unsigned(9 downto 0); signal CountAT,CountBT:unsigned(9 downto 0); signal iColB:unsigned(19 downto 0); signal irow,icol,iCountA,iCountB: unsigned(4 downto 0); signal iCountEnableAB_d1,iCountEnableAB_d2,iCountEnableAB_d3: std_logic; begin--Write Enable for RAM AiWriteEnableA(0)iWriteEnableA, addra => WriteAddress, dina => WriteData, clkb=> Clock, enb=> iReadEnableAB, addrb => std_logic_vector(iReadAddrA), doutb => iReadDataA); InputBufferB : dpram1024x16PORT MAP ( clka => Clock, wea=> iWriteEnableB, addra => WriteAddress, dina => WriteData, clkb=> Clock, enb=> iReadEnableAB, addrb => std_logic_vector(iReadAddrB), doutb => iReadDataB); OutputBufferC : dpram1024x64PORT MAP ( clka=> Clock, wea=> iWriteEnableC, addra => std_logic_vector(iCount), dina=> iWriteDataC, clkb=> Clock, enb=> ReadEnable, addrb => ReadAddress, doutb => ReadData);process(Clock,Reset)beginif(rising_edge(Clock)) thenif(Reset='1') theniCountEnableAB_d1
2019-05-17 06:30
利用Vivado, VHDL实现任意大小的矩阵乘法运算,matlab生成任意的测试数据,将仿真结果与matlab结果进行对比,最终实现全部匹配,紧急求教大神指点,可有chang.entity
2022-07-09 06:13