近日,多家通过爬虫技术开展大数据信贷风控的公司被查。短短几天时间,“爬虫”技术被推上了风口浪尖,大数据风控行业也迎来了前所未有的“震荡”。业内人士透露,这些被调查的大
2019-09-21 11:16
爬虫技术涉案大数据分析及法律解读 爬虫技术作为一种前端获取网站信息数据的技术,在目前大数据应用的背景下,异常火热。但
2021-01-12 16:39
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个
2019-03-22 16:31

而商业软件发展到今天,Web也不得不面对知识产权保护的问题,试想如果原创的高质量内容得不到保护,抄袭和盗版横行网络世界,这其实对Web生态的良性发展是不利的,也很难鼓励更多的优质原创内容的生产。
2017-12-05 16:47
爬虫开始运行时需要一个初始url,然后会根据爬取到的html文章,解析里面的链接,然后继续爬取,这就像一棵多叉树,从根节点开始,每走一步,就会产生新的节点。为了使爬虫能够结束,一般都会指定一个爬取深度(Depth)。
2018-10-23 17:01
网络爬虫在大多数情况中都不违法,其实我们生活中几乎每天都在爬虫应用,如百度,你在百度中搜索到的内容几乎都是爬虫采集下来的(百度自营的产品除外,如百度知道、百科等),所以网络爬虫
2019-03-21 17:20

模块化,函数式编程是一个非常好的习惯,坚持把每一个独立的功能都写成函数,这样会使代码简单又可复用。本次爬虫写的这么顺利,更多的是因为爬的网站是没有反爬虫技术,以及文章分类清晰,结构优美。
2018-10-31 16:54
,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。当然,信息怎么爬取、怎么存储、怎么进行分词、怎么进行相关性计算等,都是需要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2019-09-18 11:35
爬虫数据获取实战指南:从入门到高效采集 在数字化浪潮中,数据已成为驱动商业增长的核心引擎。无论是市场趋势洞察、竞品动态追踪,还是用户行为分析,爬虫技术都能助你快速捕获目标信息。然而,如何既
2025-03-24 14:08
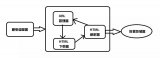
你以为你真的会写爬虫了吗?快来看看真正的爬虫架构!
2019-05-02 17:02