
k值得选取对kNN学习模型有着很大的影响。若k值过小,预测结果会对噪音样本点显得异常敏感。特别地,当k等于1时,kNN退化成最近邻算法,没有了显式的学习过程。若k值过大,会有较大的邻域训练样本进行预测,可以减小噪音
2018-09-19 17:40
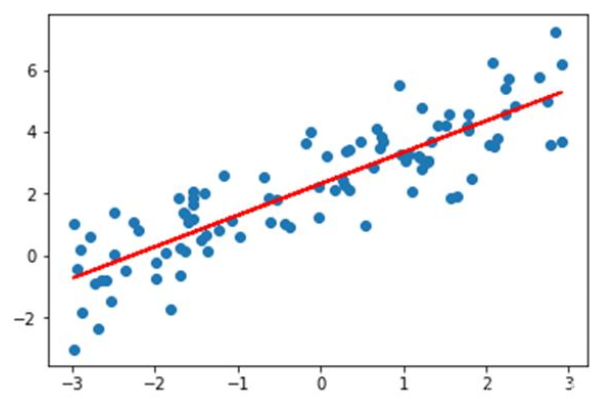
如上图所示,蓝色的点为样本点,假设x轴是房屋面积,y轴是房屋价格,那线性回归就是找到这样一条红色的直线,使得它对所有的样本做出做好的拟合,也就是距离所有的
2020-03-25 16:23
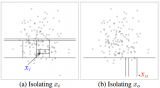
xi样本点的isolation需要大概12次划分,而异常点x0指需要4次左右。因此,我们可以根据划分次数来区分是否为异常点。但是,如何建模呢?我们容易想到:划分对应于决
2018-12-11 16:57
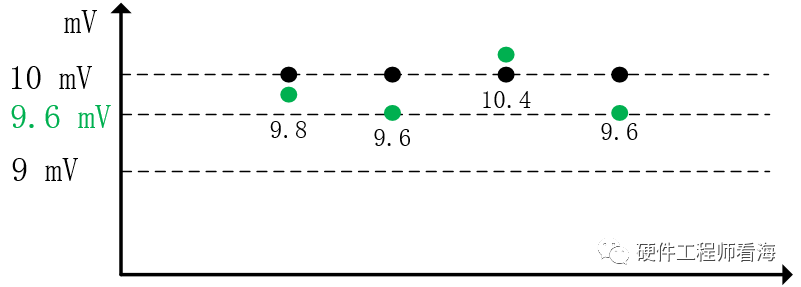
对叠加噪声后的信号进行4次采样,理论上应该得到[9.8, 9.6, 10.4, 9.6]4个离散的样本点,而受到ADC分辨率的限制
2022-11-03 10:19
为了确认注塑位置和其他形成条件对应的设计参数对最大进浇压力和翘曲变形的相关性,运行了两水平全因子设计。总样本点数为256个,每个样本点计算约8分钟,全部计算时间约为34小时。
2019-05-08 15:45

Uni3D在少样本点云部件分割任务上也展示出了卓越的性能。下表结果显示,在各种实验条件下,Uni3D的性能都明显优于Point-BERT等基线方法。
2024-01-25 10:10
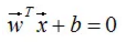
支持向量机结合了感知机和logistic回归分类思想,假设训练样本点(xi,yi)到超平面H的几何间隔为γ(γ>0),由上节定义可知,几何间隔是点到超平面最短的距离,如下图的红色直线:
2018-11-23 08:58
“纯粹基于基础的战略往往对这些因素有较长的预测视野。它们的稀少性使得它们难以评估,因为你需要等上几年才能得到足够的样本点。” 换句话说,基本原理是好的,而且肯定有一些好的策略可以利用它们。但
2019-08-02 14:51
我经常被问到这样的问题:“做假设检验时,需要的样本量是多少”, “我的实验究竟需要多少样本才有意义呢?”,这类问题可以通过功效与样本量计算来解决。 什么是功效? 所有检验都不可能尽善尽美,总存在
2022-02-08 16:12
