
k值得选取对kNN学习模型有着很大的影响。若k值过小,预测结果会对噪音样本点显得异常敏感。特别地,当k等于1时,kNN退化成最近邻算法,没有了显式的学习过程。若k值过大,会有较大的邻域训练样本进行预测,可以减小噪音
2018-09-19 17:40
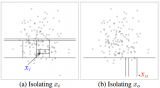
xi样本点的isolation需要大概12次划分,而异常点x0指需要4次左右。因此,我们可以根据划分次数来区分是否为异常点。但是,如何建模呢?我们容易想到:划分对应于决
2018-12-11 16:57
为了确认注塑位置和其他形成条件对应的设计参数对最大进浇压力和翘曲变形的相关性,运行了两水平全因子设计。总样本点数为256个,每个样本点计算约8分钟,全部计算时间约为34小时。
2019-05-08 15:45

Uni3D在少样本点云部件分割任务上也展示出了卓越的性能。下表结果显示,在各种实验条件下,Uni3D的性能都明显优于Point-BERT等基线方法。
2024-01-25 10:10
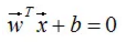
支持向量机结合了感知机和logistic回归分类思想,假设训练样本点(xi,yi)到超平面H的几何间隔为γ(γ>0),由上节定义可知,几何间隔是点到超平面最短的距离,如下图的红色直线:
2018-11-23 08:58

过去几年里,对抗样本在机器学习社区中得到了极大的关注。关于如何训练模型使它们不易受到对抗样本攻击的工作有很多,但所有这些研究都没有真正地面对这样一个基本问题:为什么这些对抗样本会出现?
2019-05-10 08:54
本文综述了康奈尔大学、康奈尔科技、谷歌Brain和Alphabet公司的基于有效样本数的类平衡损失(CB损失)。
2022-08-25 09:41
由于在训练过程中没有足够的标记图像用于所有类,这些模型在现实环境中可能不太有用。并且我们希望的模型能够识别它在训练期间没有见到过的类,因为几乎不可能在所有潜在对象的图像上进行训练。我们将从几个样本中学习的问题被称为“少样本学习 Few-Shot learning”
2022-11-01 14:21
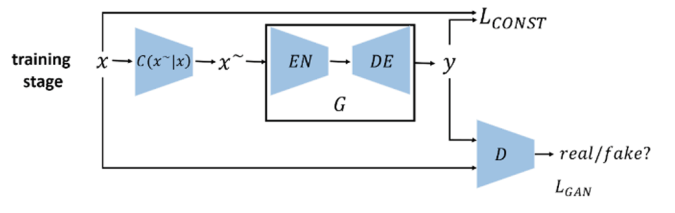
缺陷检测是工业生产过程中的关键环节,其检测结果的好坏直接影响着产品的质量。而在现实场景中,但产品瑕疵率非常低,甚至是没有,缺陷样本的不充足使得需要深度学习缺陷检测模型准确率不高。如何在缺陷样本少
2023-06-26 09:49

什么是小样本学习?它与弱监督学习等问题有何差异?其核心问题是什么?来自港科大和第四范式的这篇综述论文提供了解答。 数据是机器学习领域的重要资源,在数据缺少的情况下如何训练模型呢?小样本学习是其中一个
2023-06-14 09:59