电子发烧友
6110次浏览
范畴标注是组合范畴语法解析中的子任务之一,可用于提高解析器的效率和性能.传统的最大熵模型需要手工定义特征模板,神经网络则通过隐含层学习到离散特征的分布式表示,从而自动提取分类需要的特征.引入该模型来
2018-01-07 10:43
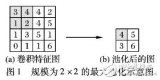
,构建一个多标签学习的卷积神经网络( CNN-MLL)模型,然后利用图像标注词间的相关性对网络模型输出结果进行改善。通过在IAPR TC-12标准图像标注数据集上对比了
2017-12-07 14:30
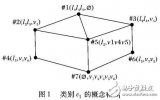
为生成有效表示图像场景语义的视觉词典,提高场景语义标注性能,提出一种基于形式概念分析( FCA)的图像场景语义标注模型。该方法首先将训练图像集与其初始的视觉词典抽象为形式背景,采用信息熵标识了各视觉
2018-01-12 15:49
本文主要分为三个方面:语义词典的构建,词语标注的数据结构和数据库语义的标注与排歧算法。其中词典用来存储数据库的语义信息,通过程序调用以标注分词后的词语;词语
2010-01-15 14:31
在中文词法分析中,分词是词性标注必须经历的阶段。为了能在分词阶段就充分利用词性标注的信息和减少两阶段错误的累计,最好的方法是将两个阶段,整合到一个架构中。该文
2010-03-06 11:22
数据标注是大模型训练过程中不可或缺的基础环节,其质量直接影响着模型的性能表现。在大模型训练中,数据标注承担着将原始数据转
2025-03-21 10:30
实体识别通常被当作序列标注任务来做,序列标注模型需要对实体边界和实体类别进行预测,从而识别和提取出相应的命名实体。在BERT出现以前,实体识别的SOTA模型是LSTM+
2022-07-28 11:08
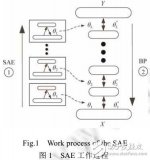
自动编码器(stacked auto-encoder,简称SAE)的自动图像标注算法。提升了标注效率和标注效果.主要针对图像标注数据不平衡问题,提出两种解决思路:对于
2017-12-28 10:59