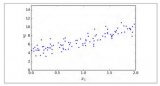
以一个简单的线性回归模型为例,讨论两种不同的训练方法来得到模型的最优解。
2018-06-22 10:02
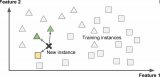
大多机器学习任务是关于预测的。这意味着给定一定数量的训练样本,系统需要能推广到之前没见到过的样本。对训练数据集有很好的性能还不够,真正的目标是对新实例预测的性能。
2018-05-25 15:34
Sklearn 与 TensorFlow 机器学习实用指南——第九章习题答案
2020-05-13 13:28

本章讨论的最后一个集成方法叫做 Stacking(stacked generalization 的缩写)。这个算法基于一个简单的想法:不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,我们为什么不训练一个模型来执行这个聚合?图 7-12 展示了这样一个在新的回归实例上预测的集成。底部三个分类器每一个都有不同的值(3.1,2.7 和 2.9),然后最后一个分类器(叫做 blender 或者 meta learner )把这三个分类器的结果当做输入然后做出最终决策(3.0)。
2018-07-27 17:40
这个损失函数是合理的,因为当 $t$ 接近 0 时,$-log(t)$ 变得非常大,所以如果模型估计一个正例概率接近于 0,那么损失函数将会很大,同时如果模型估计一个负例的概率接近 1,那么损失函数同样会很大。 另一方面,当 $t$ 接近于 1 时,$-log(t)$ 接近 0,所以如果模型估计一个正例概率接近于 0,那么损失函数接近于 0,同时如果模型估计一个负例的概率接近 0,那么损失函数同样会接近于 0, 这正是我们想的。
2018-06-29 15:02
分析混淆矩阵通常可以给你提供深刻的见解去改善你的分类器。回顾这幅图,看样子你应该努力改善分类器在数字 8 和数字 9 上的表现,和纠正 3/5 的混淆。举例子,你可以尝试去收集更多的数据,或者你可以构造新的、有助于分类器的特征。举例子,写一个算法去数闭合的环(比如,数字 8 有两个环,数字 6 有一个, 5 没有)。又或者你可以预处理图片(比如,使用 Scikit-Learn,Pillow, OpenCV)去构造一个模式,比如闭合的环。
2018-06-19 15:08

受试者工作特征(ROC)曲线是另一个二分类器常用的工具。它非常类似与准确率/召回率曲线,但不是画出准确率对召回率的曲线,ROC 曲线是真正例率(true positive rate,另一个名字叫做召回率)对假反例率(false positive rate, FPR)的曲线。FPR 是反例被错误分成正例的比率。它等于 1 减去真反例率(true negative rate, TNR)。TNR是反例被正确分类的比率。TNR也叫做特异性。所以 ROC 曲线画出召回率对(1 减特异性)的曲线。
2018-06-19 15:20
机器学习实践指南——案例应用解析
2018-04-13 16:40
本文旨在为硬件和嵌入式工程师提供机器学习(ML)的背景,它是什么,它是如何工作的,它为什么重要,以及 TinyML 是如何适应的机器学习是一个始终存在并经常被误解的技术
2022-06-21 11:06
本指南适用于系统设计人员,可能使用Arm Flexible access程序。 本指南将帮助您开发可以执行机器学习的片上系统(SoC)在边缘。本
2023-08-02 11:02