1.整体思路第一步:先将中文文本进行分词,这里使用的HanLP-汉语言处理包进行中文文本分词。第二步:使用停用词表,去除分好的词中的停用词。2.中文文本分词环境配置使用的HanLP-汉语言处理包
2019-04-30 09:38
基于AdaBoost_Bayes算法的中文文本分类系统_徐凯
2017-01-07 18:56
社交网络作为社会生活不可或缺的一部分,针对其产生的文本数据进行情感分析已成为自然语言处理领域的一个研究热点。鉴于深度学习技术能够自动构建文本特征,人们已提出CNN( convolutional
2021-06-15 11:28
目前来看,TouchGFX显示的中文好像都是固定的。但是如果我串口收到一个中文unicode的编码,要将其显示出来,或者用户通过键盘,编辑任意中文文本的话,要怎么实现呢?
2024-04-09 08:23

基于神经网络的文本蕴含识别模型通常仅从训练数据中学习推理知识,导致模型泛化能力较弱。提出种融合外部语义知识的中文知识增强推理模型( CKEIM)。根据知网知识库的特点提取词级语义知识特征以构建注意力
2021-03-12 13:50
文本聚类是中文文本挖掘中的一种重要分析方法。K 均值聚类算法是目前最为常用的文本聚类算法之一。但此算法在处理高维、稀疏数据集等问题时存在一些不足,且对初始聚类
2010-01-15 14:24
机器学习基础教程实践(一)——中文的向量化
2019-08-27 14:19
JAVA教程之压缩中文文件名的文件,很好的JAVA的资料,快来学习吧
2016-04-11 17:28
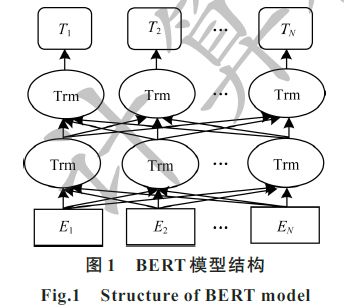
针对现有中文短文夲分类算法通常存在特征稀疏、用词不规范和数据海量等问题,提出一种基于Transformer的双向编码器表示(BERT)的中文短文本分类算法,使用BERT预训练语言模型对短
2021-03-11 16:10

RFC791中文文档
2017-09-18 09:42