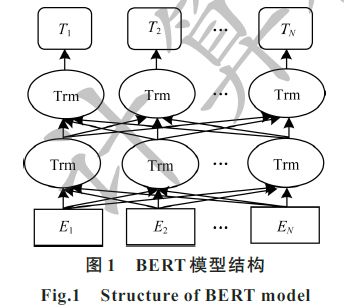
针对现有中文短文夲分类算法通常存在特征稀疏、用词不规范和数据海量等问题,提出一种基于Transformer的双向编码器表示(BERT)的中文短文本分类算法,使用BERT
2021-03-11 16:10
传统的文本分类方法仅使用一种模型进行分类,容易忽略不同类别特征词出现交叉的情况,影响分类性能。为提高文本分类的准确率,提岀基于主题相似性聚类的
2021-05-12 16:25

为提高旅游问句文本中关键特征的利用率,提出一种集成词级卷积神经网络(WL-CNN)与句级双向长短期记忆(SL-Bi-LSTM)网络的旅游问句文本分类算法。利用 WL-CNN和SL-Bi-LSTM分别
2021-03-17 15:24

基于BERT模型的社交电商文本分类算法。首先,该算法采用BERT( Bidirectional Encoder Representations from Transformers)预训练语言模型来完成社交电商
2021-04-13 15:14
基于向量空间模型的文本分类方法的文本表示具有高纬度、高稀疏的特点,特征表达能力较弱,且特征工程依赖人工提取,成本较髙。针对该问题,提出基于双通道词向量的卷积胶囊网络文本分类算法
2021-05-24 15:07
朴素贝叶斯(NB)算法应用于文本分类时具有简单性和高效性,但算法中属性独立性与重要性一致的假设,使其在精确度方面存在瓶颈。针对该问题,提出一种基于泊松分布的特征加权NB文本分类
2021-05-28 11:30
针对在文本分类中先验概率的计算比较费时而且对分类效果影响不大、后验概率的精度损失影响分类准确率的现象,对经典朴素贝叶斯分类算法
2018-03-05 11:19
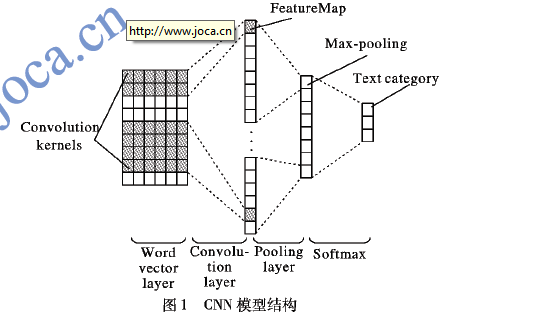
采样的主动学习算法(DBC-AL)选择对分类模型贡献率较高的样本进行标注,以低标注代价获得高质量模型训练集;然后,结合SVD算法建立SVD-CNN弹幕文本分类模型,使用
2019-05-06 11:42
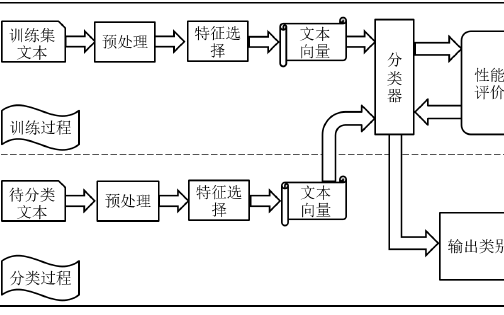
针对传统文本分类算法在面对日益增多的海量文本数据时效率低下的问题,论文在Spark计算框架上设计并实现了一种并行化朴素贝叶斯文本分类器,并着重介绍了基于Spark计算框
2018-12-18 14:19
主题概率分布,提出一种文本分类算法NLDA。在 Thucnews语料库和复旦大学语料库上进行实验,结果表明,与传统LDA模型相比,该算法的平均分类准确率分别提升5.53
2021-05-25 15:20