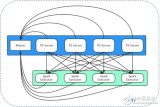
众所周知,自2015年以来微博的业务发展迅猛。如果根据内容来划分,微博的业务有主信息(Feed)流、热门微
2017-09-28 17:52
基于主动学习的微博聚类分析_朱丽
2017-01-07 16:24
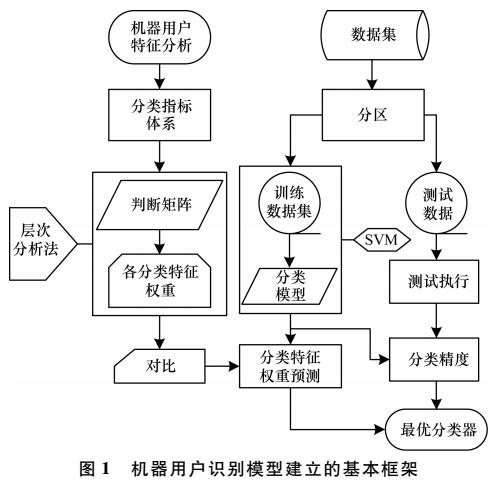
以新浪微博中的用户为研究对象,分析并提取机器用户的特征,提出一种新的微博机器用户检测方法。通过层次分析法构建分类指标体系,对各指标特征进行量化评估,利用支持向量机(SV
2018-02-08 15:36
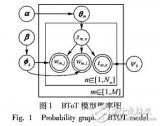
针对传统主题模型忽略了微博短文本和文本动态演化的问题,提出了基于微博文本的词对主题演化( BToT)模型,并根据所提模型对数据集进行主题演化分析。BToT模型在文本生成
2017-12-03 11:31
探究微博转发网络的构建机制有助于深刻理解信息在微博平台上的传播过程,得出针对微博
2018-01-14 14:52
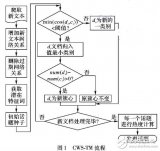
针对微博的实时性、稀疏性和海量性特点,提出基于实时词共现网络的话题发现模型。首先,从原始语料中筛选出主题词集合,再利用时间参数计算共现主题词的关系权重以实现词共现网络的构建,通过该网络推算出与话题
2017-12-19 18:56
随着微博用户的不断增加,微博网络已成为用户进行信息交流的平台,针对由于博文长度受限,传统的社区发现算法无法有效解决
2018-01-02 16:26
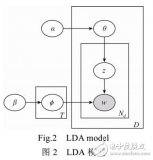
由于微博文本的长度较短,直接使用隐狄利克雷分布(LDA)模型会导致特征向量高维稀疏。为此,提出种融合标签语义的热点话题挖掘方法。利用公共块算法计算微博标签的相似度,合并
2021-05-25 14:53
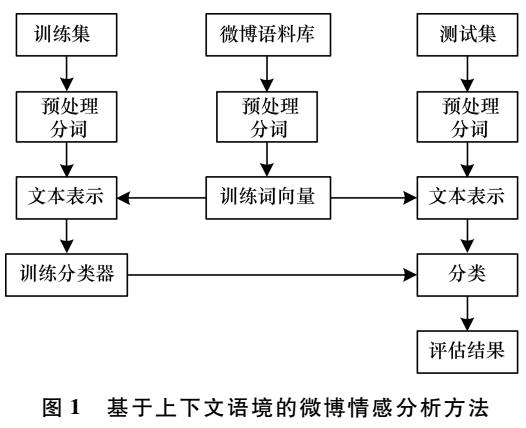
传统情感分析方法仅考虑单一文本,对长度短小且口语化严重的微博文本情感极性识别率较低。针对上述问题,提出一种结合上下文消息的情感分析方法。将微博情感分析问题看做标签序列学
2018-02-24 11:34

结合微博新词的构词规则自由度大和极其复杂的特点,针对传统的C/NC-value方法抽取的结果新词边界的识别准确率不高,以及低频微博新词无法正确识别的问题,提出了一种融合
2017-12-04 15:31