为了进一步提高在Spark平台上的频繁模式增长(FP-Growth)算法执行效率,提出一种新的基于Spark的并行
2018-11-23 19:17
[源码和文档分享]基于Python实现的Apriori算法和FP-Growth算法的频繁项集挖掘的研究与实现
2020-06-04 12:49
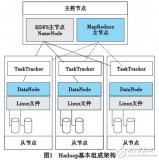
问题,提出了基于Hadoop的负载均衡数据分割FP-Growth并行算法。在Hadoop平台下,使用负载均衡和数据分割相结合的方式对原始事务数据集分片实现并行化。实验证
2018-01-14 16:41
一种基于事务中项间联通权重矩阵的负载平衡并行频繁模式增长算法CWBPFP。算法在Spark框架上实现并行计算,数据分组时
2017-11-17 17:50
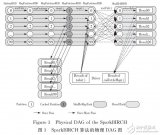
在分布式计算和内存为王的时代,Spark作为基于内存计算的分布式框架技术得到了前所未有的关注与应用。着重研究BIRCH算法在Spark上并行
2017-11-23 11:24

为了提髙关联规则挖掘效率’文中提出了一种适用于 Spark平台的并行仳FP_ growth关联规则挖掘方法。首先,利用Spark
2021-04-23 13:59
针对传统矩阵分解算法在处理海量数据信息时所面临的处理速度和计算资源的瓶颈问题,利用Spark在内存计算和迭代计算上的优势,提出了Spark框架下的矩阵分解并行
2018-01-02 11:31
如何實現按下布爾按鈕程序運行,用不點程序左上角的運行鍵。
2013-02-05 14:14
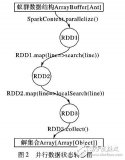
为应对大数据时代中组合优化问题的求解,基于云计算框架Spark,借助其基于内存、分布式的特定,提出一种并行蚁群优化算法。其思路是通过将蚂蚁构造为弹性分布式数据集,由此给出相应的一系列转换算予,实现了
2018-01-02 14:11
