
机器学习算法是数据挖掘、数据能力分析和数学建模必不可少的一部分,而随机森林算法和决策树算法是其中较为常用的两种算法,本文
2023-09-21 11:17
随机森林是一种灵活且易于使用的机器学习算法,即便没有超参数调优,也可以在大多数情况下得到很好的结果。它也是最常用的算法之一,因为它很简易,既可用于分类也能用于回归任务。 在这篇文章中,你将了解到随机
2018-03-14 16:10
K-Means是十大经典数据挖掘算法之一。K-Means和KNN(K邻近)看上去都是K打头,但却是不同种类的
2018-07-05 14:18
K-means 算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。而簇是由距离靠近的对象组成的,因此
2022-07-18 09:19
K近邻KNN(k-Nearest Neighbor)算法,也叫K最近邻算法,1968年由 Cover 和 Hart 提出
2018-05-29 06:53
随机森林是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能,因此,随机森林也被誉为“代
2022-10-10 17:14
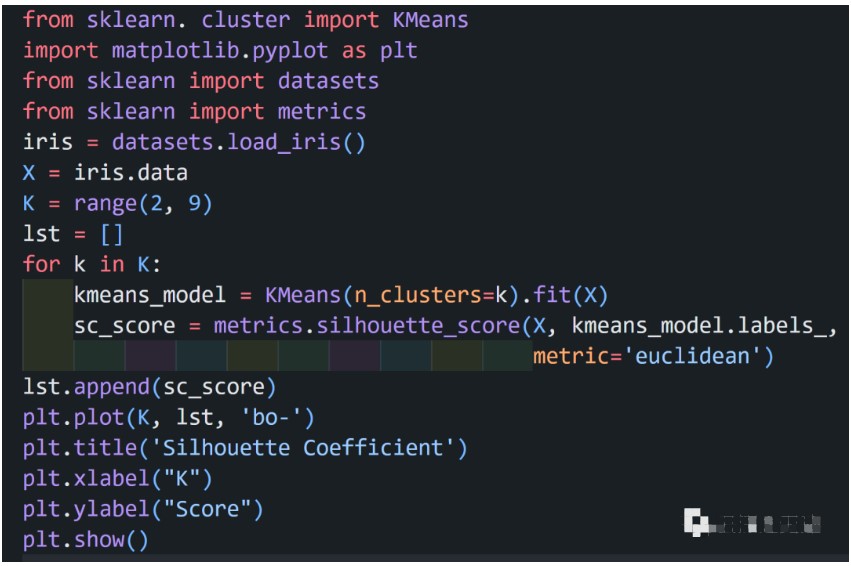
对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的
2018-02-12 16:06
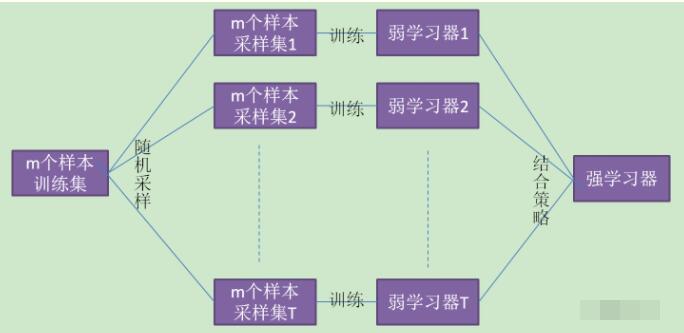
集成学习有两个流派,一个是boosting,特点是各个弱学习器之间有依赖关系;一个是bagging,特点是各个弱学习器之间没依赖关系,可以并行拟合。
2020-12-09 13:58

KNN(k-Nearest Neighbors)思想简单,应用的数学知识几乎为0,所以作为机器学习的入门非常实用、可以解释机器学习算法使用过程中的很多细节问题。能够更加完整地刻画机器学习应用的流程。
2023-06-06 11:15
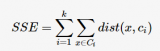
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
2018-07-24 17:44