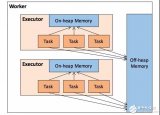
作为一个 JVM 进程,Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开
2018-06-04 03:44
数据挖掘主要分为三类:分类算法、聚类算法和相关规则,基本涵盖了当前商业市场对算法的所有需求。这三类包含了许多经典算法。市面上很多关于数据挖掘算法的介绍都是深奥难懂的。今天我就用我的理解给大家介绍一下数据挖掘十大经典算
2023-09-14 15:56
Apache Spark是处理和使用大数据最广泛的框架之一,Python是数据分析、机器学习等领域最广泛使用的编程语言之一。如果想要获得更棒的机器学习能力,为什么不将Spark和Python一起使用呢?
2018-07-01 10:15
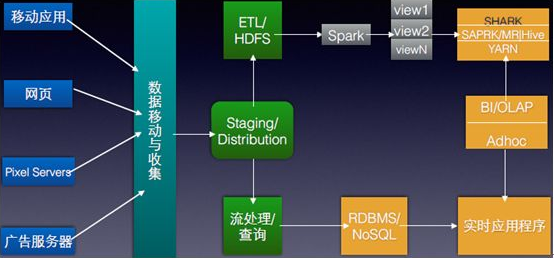
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
2018-02-12 14:41
数据挖掘与传统意义上的统计学不同。统计学推断是假设驱动的,即形成假设并在数据基础上验证他;数据挖掘是数据驱动的,即自动地从数据中提取模式和假设。数据挖掘的目标是提取可以容易转换成逻辑规则或可视化表示的定性模型,与传统
2017-12-31 12:19
数据挖掘工程师多是通过对海量数据进行挖掘,寻找数据的存在模式,从而通过数据挖掘来解决具体问题。其更多是针对某一个具体的问题,是以解决具体问题为导向的。
2017-12-31 12:41
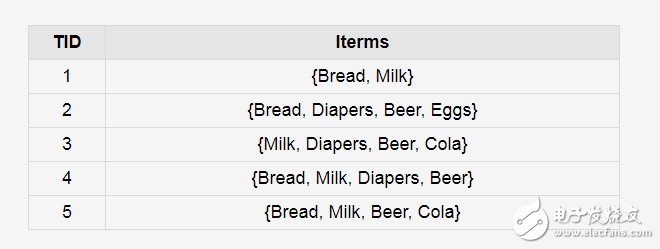
关联分析是一类非常有用的数据挖掘方法,能从数据中挖掘出潜在的关联关系。Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推
2018-02-04 09:37

Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。而且算法已经被广泛的应用到商业、网络安全等各个领域。
2018-02-04 09:30
如果你完全不懂scala但又想用Spark Mllib,你可能得向scala妥协。这不是理想的解决方案,但却是实际的解决方案。让它运作,然后把它变得更好。相比找到一种不变的、看似完美的解决方案,学会新的东西并让它发挥作用才更令人开心。
2018-03-31 10:34
数据挖掘可以认为是数据库技术与机器学习的交叉,它利用数据库技术来管理海量的数据,并利用机器学习和统计分析来进行数据分析。
2018-01-05 15:20