K-means算法是最简单的一种聚类算法。算法的目的是使各个样本与所在类均值
2017-12-01 14:07
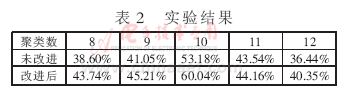
Web文档聚类中k-means算法的改进 介绍了Web文档聚类中普遍使用的、基于分割的k-means
2009-09-19 09:17
K-means 是一种聚类算法,且对于数据科学家而言,是简单且热门的无监督式机器学习(ML)算法之一。
2022-06-06 11:53
在聚类技术领域中,K-means可能是最常见和经常使用的技术之一。K-means使用迭代细化方法,基于用户定义的集群数量(由变量K表示)和数据集来产生其最终
2022-10-28 14:25

尽可能归于一类,而把不相似的样本划分到不同的类中。硬聚类把每个待识别的对象严格的划分某类中,具有非此即彼的性质,而模糊聚类建立了样本对类别的不确定描述,更能客观的反应客观世界,从而成为聚类分析的主流。
2017-12-01 14:26
这一最著名的聚类算法主要基于数据点之间的均值和与聚类中心的聚类迭代而成。它主要的优点是十分的高效,由于只需要计算数据点与
2020-04-15 15:23
几张GIF理解K-均值聚类原理k均值聚类数学推导与python实现前文说
2020-12-10 21:56
均值滤波是典型的线性滤波算法,它是指在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标像素为中心的周围个像素,构成一个滤波模板,即去掉目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。
2017-12-19 15:35
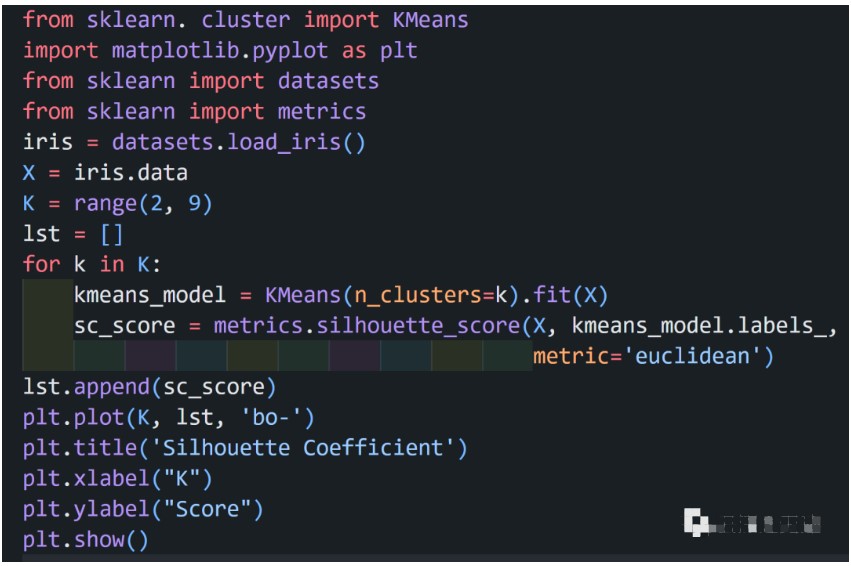
K-means 算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。而簇是由距离靠近的对象组成的,因此
2022-07-18 09:19
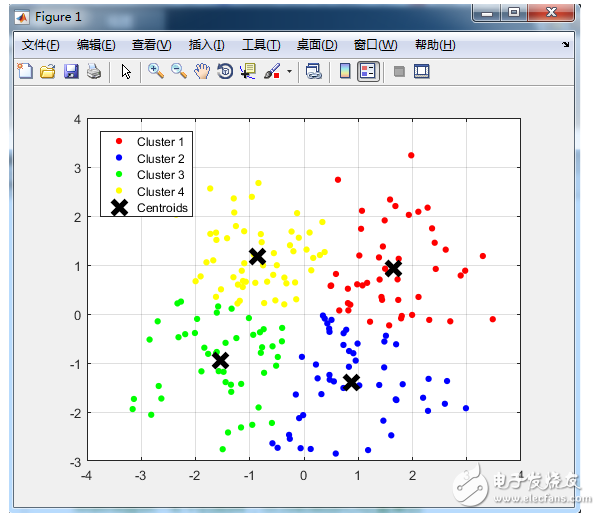
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场
2018-02-12 16:42