前面一口君写了一篇关于url的文章:《一文带你理解URI 和 URL 有什么区别?》
2022-04-14 12:55
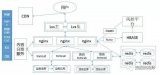
1 秒杀业务分析 正常电子商务流程 (1)查询商品;(2)创建订单;(3)扣减库存;(4)更新订单;(5)付款;(6)卖家发货 秒杀业务的特性 (1)低廉价格;(2)大幅推广;(3)瞬时
2023-06-29 11:12

MoreFind 一款用于快速导出URL、Domain和IP的小工具 快速安装 方式一: 通过Go包管理安装 go install github.com/mstxq17
2023-05-25 14:11
【git remote set-url origin URL】 更换远程仓库地址,URL为新地址。
2023-12-18 09:35

ADI将在本文概述一些利用低成本电源转换器成功实现高质量产品的应用实例。
2023-07-08 15:03
urllib.parse – 用于打破统一资源定位器(URL)的字符串在组件(寻址方案,网络位置,路径等)之间的隔断,为了结合组件到一个URL字符串,并将“相对URL”转化为一个绝对
2018-04-24 17:03

tart_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
2018-12-07 16:12
获取网页内容,匹配有地址的文本 :param url: 获取地址的url :return: 返回包含地址的网页内容
2023-03-03 14:54
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。
2018-06-26 11:52
后来发现,其电视剧链接都是在文章里面,然后文章url后面有个数字编号,就像这样的http://cn163.net/archives/24016/,所以机智的我又用了之前写过的爬虫经验,解决方法就是
2019-04-16 12:52