过拟合是指模型在训练集上表现很好,到了验证和测试阶段就大不如意了,即模型的泛化能力很差。
2020-01-29 17:48
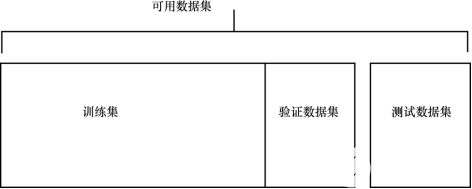
本章涵盖了以下主题: · 分类和回归之外的其他类型的问题; · 评估问题,理解过拟合、欠拟合,以及解决这些问题的技巧; · 为深度学习准备数据。 请记住,在本章中讨论的
2022-07-12 09:28
今天要写的是关于机器学习和深度学习中的一项关键技术:正则化。相信在机器学习领域摸爬滚打多年的你一定知道正则化是防止模型过拟合的核心技术之一,关于欠拟合和
2018-08-14 11:58

由于添加了这个正则化项,各权值被减小了,换句话说,就是神经网络的复杂度降低了,结合“网络有多复杂,过拟合就有多容易”的思想,从理论上来说,这样做等于直接防止过拟合(奥卡
2018-04-27 15:23
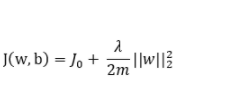
为了训练出高效可用的深层神经网络模型,在训练时必须要避免过拟合的现象。过拟合现象的优化方法通常有三种。
2020-12-02 14:17

在数据科学学科中, 过度拟合(overfit)模型被解释为一个从训练集(training set)中得到了高方差(variance)和低偏差(bias),导致其在测试数据中得到低泛化(generalization)的模型。
2018-02-07 17:00
在深度学习的广阔领域中,模型训练的核心目标之一是实现对未知数据的准确预测。然而,在实际应用中,我们经常会遇到一个问题——过拟合(Overfitting)。过拟合是指模型
2024-07-09 15:56
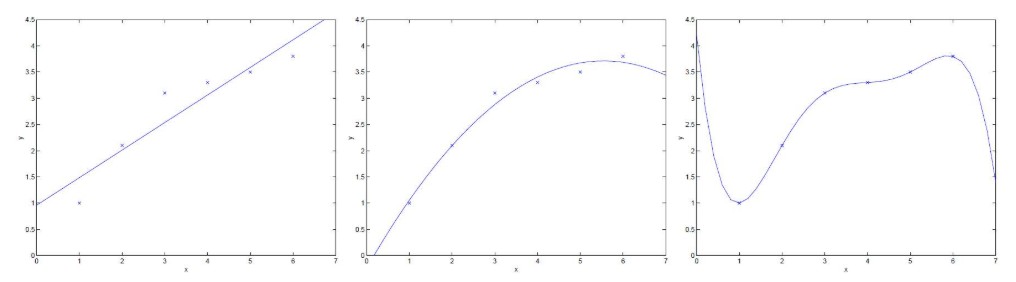
给出多个点,然后根据这些点拟合出一条直线,这个最常见的算法是多约束方程的最小二乘拟合,如下图所示:
2022-08-26 10:36
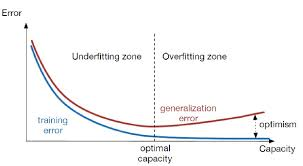
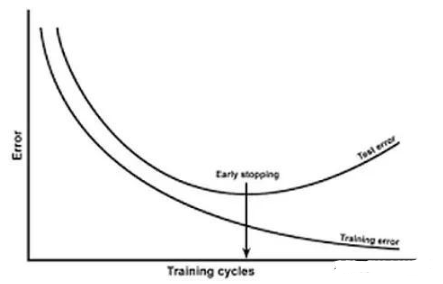
如何判断过拟合呢?我们在训练过程中会定义训练误差,验证集误差,测试集误差(泛化误差)。训练误差总是减少的,而泛化误差一开始会减少,但到一定程序后不减反而增加,这时候便出现了过拟合的现象。
2022-02-12 15:49
丢弃法是一种避免神经网络过拟合的正则化技术。像L1和L2这样的正则化技术通过修改代价函数来减少过拟合。而丢弃法修改神经网络本身。
2020-02-04 11:30