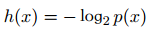
如果有人告诉我们一个相当不可能的事件发生了,我们收到的信息要多于我们被告知某个很可能发⽣的事件发⽣时收到的信息。如果我们知道某件事情⼀定会发⽣,那么我们就不会接收到信息。 也就是说,信息量应该连续依赖于事件发生的概率分布p(x)。
2018-05-09 15:04
Keras有一个简洁的API来查看模型的每一层输出尺寸,这在调试网络时非常有用。现在在PyTorch中也可以实现这个功能。
2022-08-18 11:01
这篇小文将告诉你:Softmax是如何把CNN的输出转变成概率,以及交叉熵是如何为优化过程提供度量,为了让读者能够深入理解,我们将会用python一一实现他们。
2018-07-29 11:21
什么情况下产生的平均惊喜最高呢?自然是不确定越高平均惊喜越高。对于给定均值和方差的连续分布,正态分布(高斯分布)具有最大的信息熵(也就是平均惊喜)。
2022-11-16 15:35

这样就可以计算出某一种可能性的信息量。举一个例子,假设你拿出了你的电脑,按下开关,会有三种可能性,下表列出了每一种可能的概率及其对应的信息量
2018-07-03 11:32

纵轴是"Bits for words", 这也是交叉熵的一个单位。在计算交叉熵时,如果使用以 2 为底的对数,
2023-11-22 16:08
函数有以下几种: 交叉熵损失函数 :交叉熵(Cross Entropy)是一种评估两个概率分布之间差异的度量方法,即通过比较模型预测的概率分布和真实概率分布之间的差异,
2024-11-15 10:16
Loss、分位数损失 Quantile Loss、交叉熵损失函数 Cross Entropy Loss、Hinge 损失 Hinge Loss。主要介绍各种损失函数的基本形式、原理、特点等方面。
2020-10-09 16:36

在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方法。一旦图像、视频、标注图像都可以表示为序列,则训练的模型可以在预测下一个 token 时最小化交叉熵损失。
2023-12-05 15:34
从随机量子电路进行采样是量子计算机的一个很好的校准基准,我们称之为交叉熵基准。一个成功的随机电路量子霸权实验将证明大规模容错量子计算机的基本构建块。此外,量子物理学还没有对如此高度复杂的量子态进行过测试。
2018-05-07 15:18