进入大数据时代,爬虫技术越来越重要,因为它是获取数据的一个重要手段,是大数据和云计算的基础。那么,爬虫到底是如何实现数据的获取的呢?今天和大家分享的就是一个系统学习爬虫技术的过程:先掌握
2019-01-02 16:30
什么是爬虫?爬虫的价值?最简单的python爬虫爬虫基本架构
2020-11-05 06:13
如何用Python爬虫实现百度图片自动下载?
2019-05-23 14:55
此文档包含多个python爬虫项目
2018-03-26 09:29
虽然网络机器人下载一些公开的文章和博文并不是什么大事,但是如果网络机器人在你的网站上创造了几千个账号并开始向所有用户发送垃圾邮件,就是一个大问题了。网络表单,尤其是那些用于账号创建和登录的网站,如果
2019-12-12 17:39
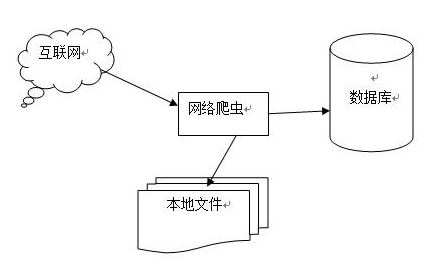
脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。爬虫从初始网页的url开始, 不断从当前页面抽取新的url放入队列。直到满足系统给定的停止条件才停止。可以为搜素引擎从互联网中下载网页数据,是搜素引擎的重要组成部分。2. 软件配置python 3.
2022-01-11 06:32
随着互联网的发展进步,现在互联网上也有许多网络爬虫。网络爬虫通过自己爬虫程序向目标网站采集相关数据信息。当然互联网的网站会有反爬策略。比如某电商网站就会限制一个用户IP的访问频率,从而出现验证码
2020-09-01 17:23
你以为你真的会写爬虫了吗?快来看看真正的爬虫架构!
2019-05-02 17:02
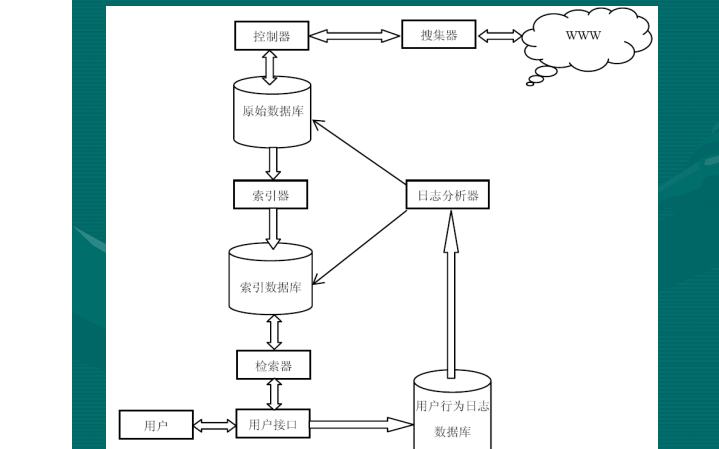
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直
2019-12-04 08:00
imdbcn爬虫实例 imdbcn网站结构分析 创建爬虫项目 运行imdb爬虫
2020-11-05 07:07