K-Means是十大经典数据挖掘算法之一。K-Means和KNN(K邻近)看上去都是
2018-07-05 14:18
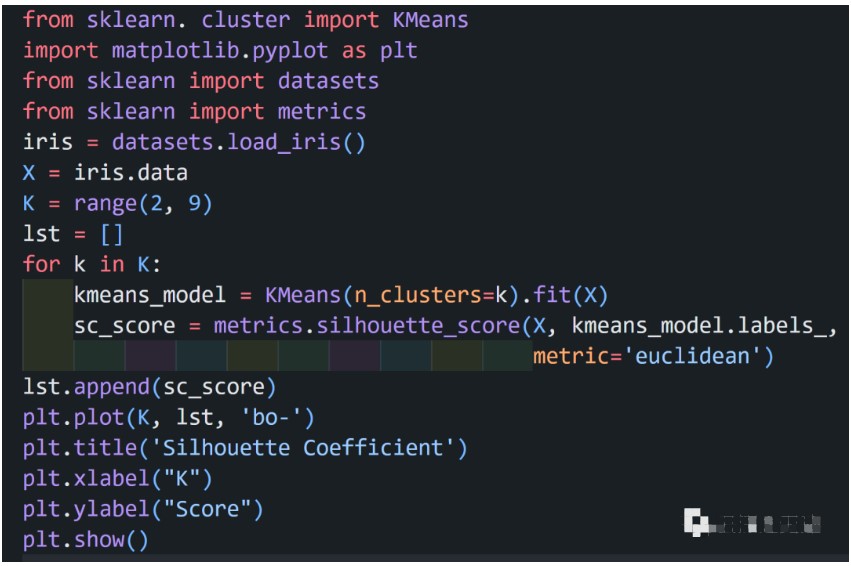
K-means 算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。而簇是
2022-07-18 09:19

无监督学习是机器学习技术中的一类,用于发现数据中的模式。本文介绍用Python进行无监督学习的几种聚类
2018-05-27 09:59
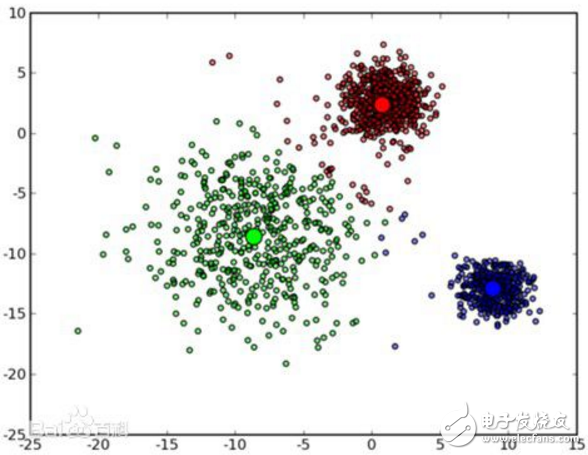
K-means算法的优点是:首先,算法能根据较少的已知聚类样本的类别对树进行剪枝确定部分样本的分类;其次,为克服少量样本
2018-02-12 16:27
对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的
2018-02-12 16:06
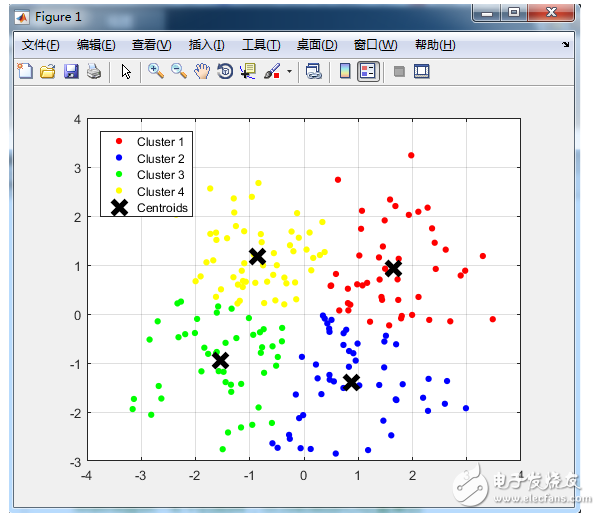
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚
2018-02-12 16:42
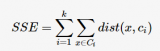
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结
2018-07-24 17:44

图像分割:利用图像的灰度、颜色、纹理、形状等特征,把图像分成若干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区域之间存在明显的差异性。然后就可以将分割的图像中
2023-09-07 16:59

本文针对k-medoids算法具有初始点选取复杂、聚类迭代时间久、中心点选取消耗资源过多等缺点,使用Hadoop平台下的MapReduce编程框架对
2018-05-18 09:06
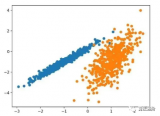
有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类
2023-05-22 09:13